JavaScript学习笔记:querySelectorAll 和 getElementsByTagName区别
在《DOM的操作》一节中知道querySelectorAll()和getElementsByTagName()两个方法都是用来查找DOM元素的。通过上一节的学习,知道querySelectorAll()方法将获取到NodeList对象,getElementsByTagName()方法获取到的是HTMLCollection对象。虽然他们获取的都是DOM动态集合,但两者还是略有差异的。今天我们就来看这两者之间的区别。
有关于querySelectorAll()和getElementsByTagName()两者的区别,这里推荐几篇文章:
- @Jin的《简单讨论
querySelectorAllVsgetElementsByTagName区别》 - @Nicholas C. Zakas 的《Why is
getElementsByTagName()faster thanquerySelectorAll()?》 - 《为什么
getElementsByTagName比querySelectorAll方法快》
为了能理解这两者之间的区别,接下来的内容和整个思路是跟着上面几篇文章进行的。
区别之处
稍微接触过JavaScript的同学都应该知道,querySelectorAll()和getElementsByTagName()两个方法都是用来从DOM树中获取元素集合。如果简单的理解就是用来选择DOM元素。虽然表面上都是用来选择DOM元素,但事实并非如此,两者之间还有很大的区别:
querySelectorAll() |
getElementsByTagName() |
|
|---|---|---|
| 遍历方式 | 深度优先 | 深度优先 |
| 返回值类型 | NodeList集合 |
HTMLCollection集合 |
| 返回值状态 | 静态 | 动态 |
如果阅读过上一节的内容,对于querySelectorAll()和getElementsByTagName()返回值的类型与状态,都有了一定的了解,但这里所说的遍历方式:深度优先 还是初次接触这个概念。那么为了后面的内容更易于理解,很有必要了解一下。
深度优先遍历
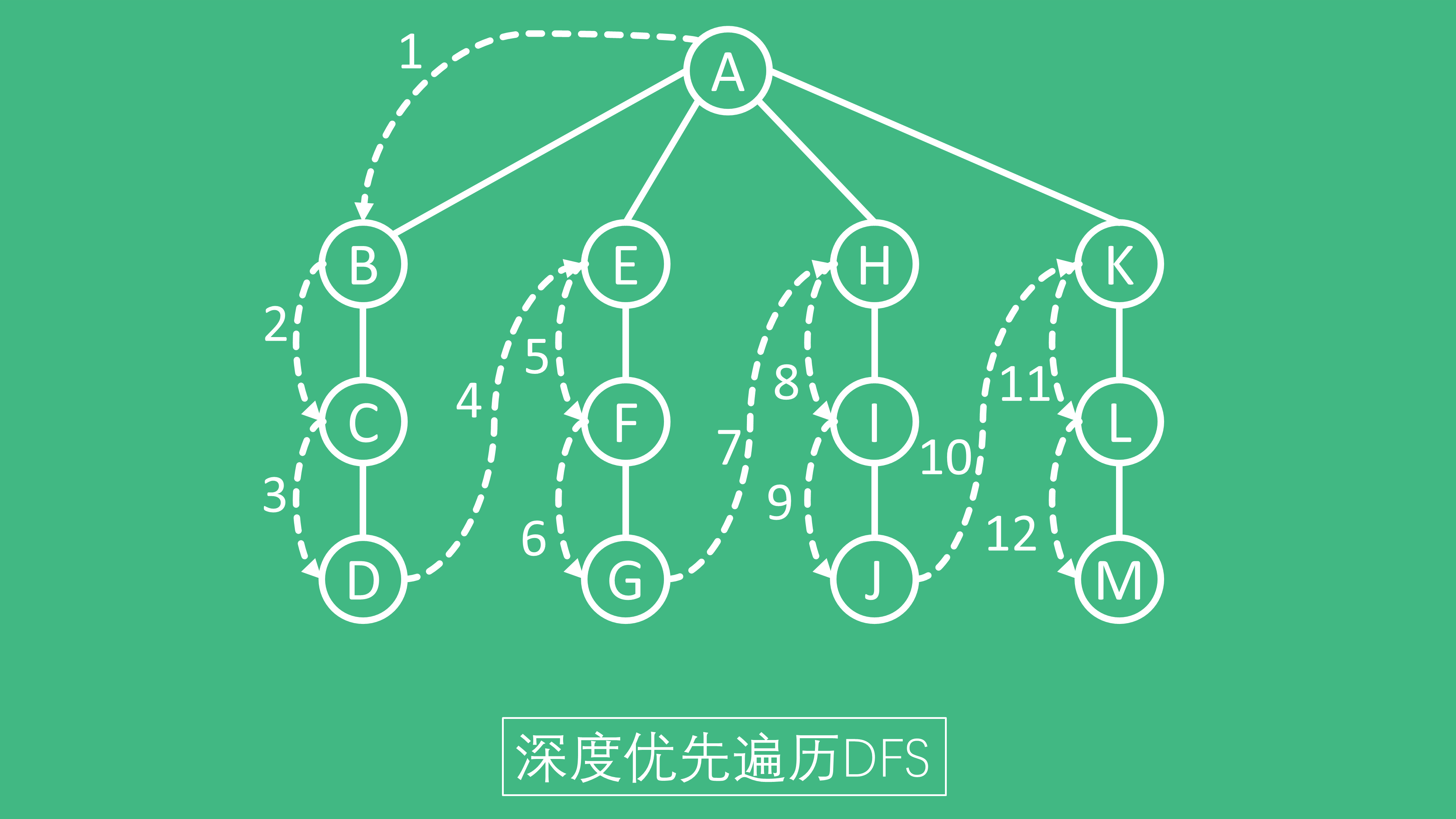
深度优先搜索算法(英语:Depth-First-Search,简称DFS)是一种用于遍历或搜索树或图的算法。沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点
v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。属于盲目搜索。
简单点来描述:深度优先遍历从一路径的起始点开始追溯,直到遍历该路径的最后一个节点,然后回溯,继续追溯下一路径,依次类推,直到遍历完成。如上图所示。
深度优先遍历实现相对简单,通过递归即可完成。不断递归,直到本路径最后一个节点,然后回溯,继续递归。
除了深度优先遍历之外,还有广度优先遍历:
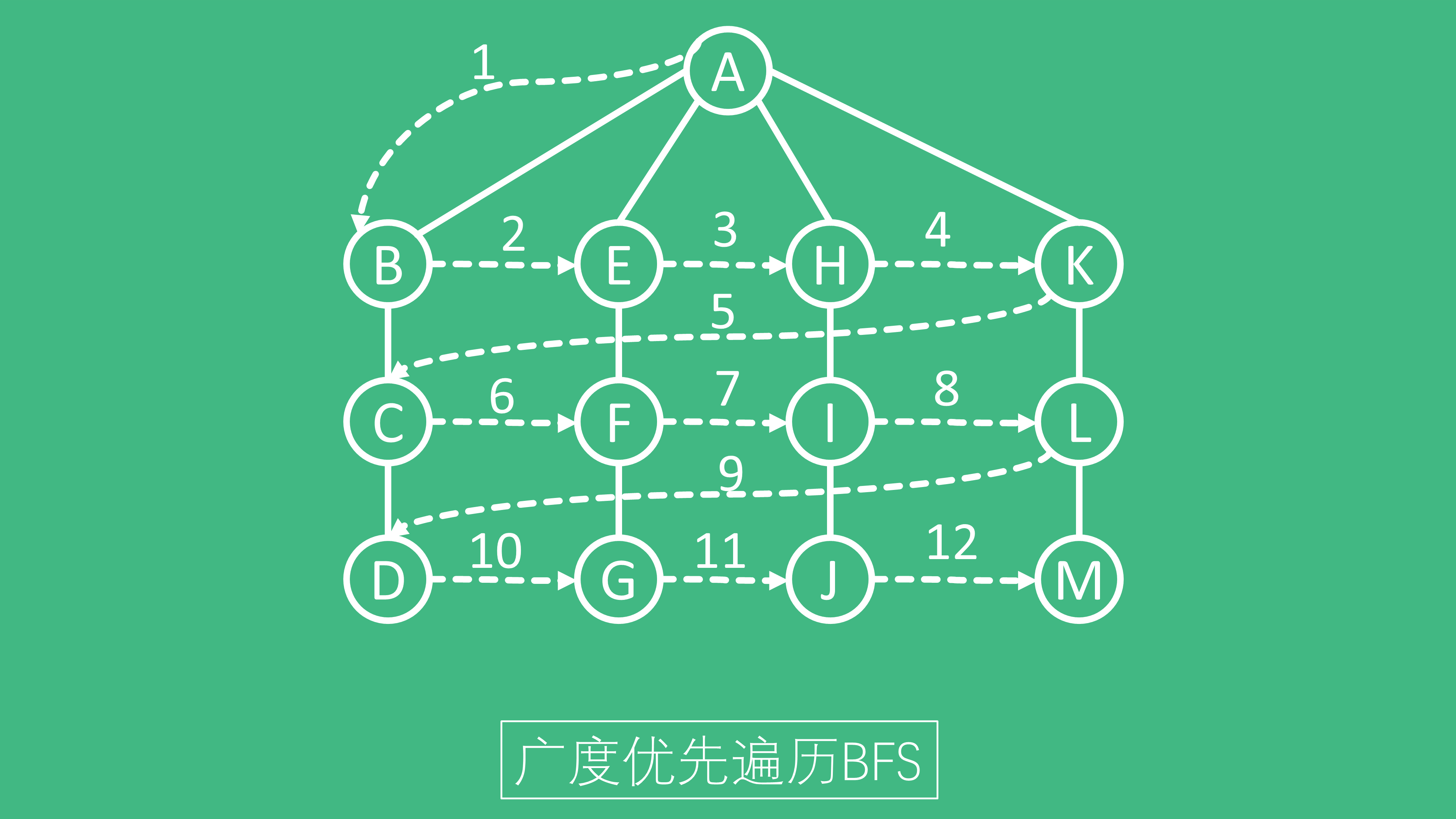
广度优先搜索算法(英语:Breadth-First-Search,缩写为BFS),又译作宽度优先搜索,或横向优先搜索,是一种图形搜索算法。简单的说,BFS是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。广度优先搜索的实现一般采用open-closed表。
广度优先遍历,则优先遍历同一层次最邻近的节点,然后再往下遍历上一层首个节点的下层节点。如下图所示:
DOM的结构和数据结构中的“树”型结构比较类似,所以很自然的就可以使用DFS和BFS进行遍历。
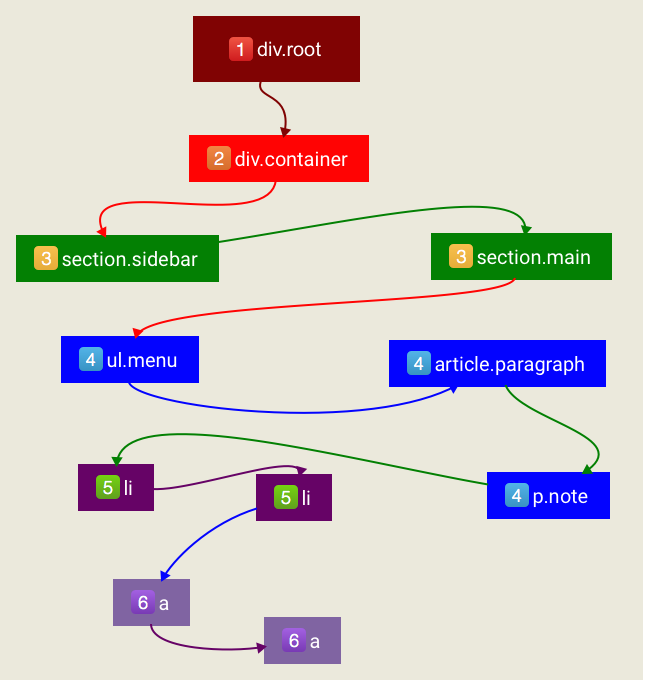
比如我们有一个这样的HTML结构:
<div class="root">
<div class="container">
<section class="sidebar">
<ul class="menu">
<li>
<a></a>
</li>
<li>
<a></a>
</li>
</ul>
</section>
<section class="main">
<article class="paragraph"></article>
<p class="note"></p>
</section>
</div>
</div>
对应的DOM树结构如下图所示:
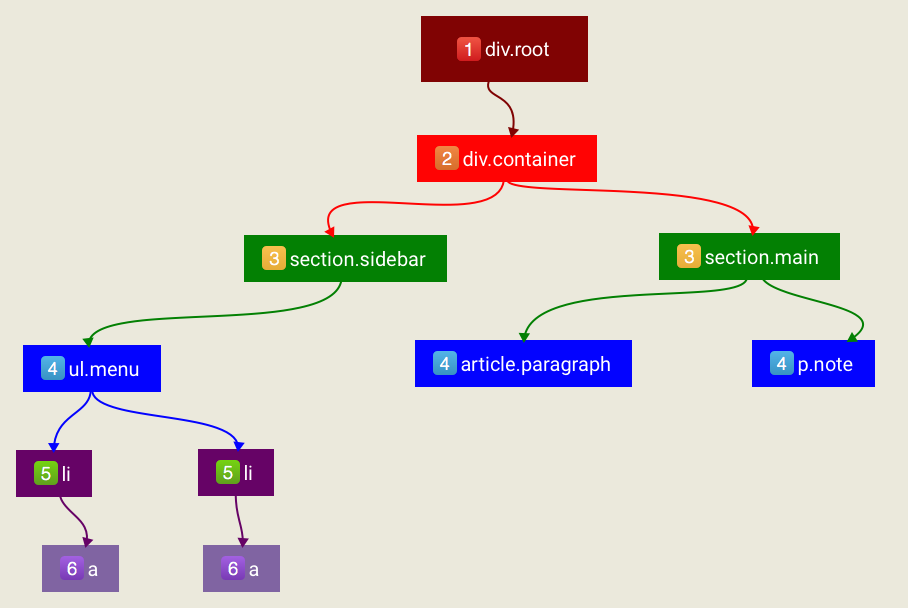
对于DOM树的深度优先遍历,执行的结果应该如下:

写个函数来实现深度优先遍历:
const DFS = function(node) {
if (!node) {
return
}
let deep = arguments[1] || 1
console.log(`${node.nodeName}.${node.classList} ${deep}`)
if (!node.children.length) {
return
}
Array.from(node.children).forEach((item) => DFS(item, deep + 1))
}
DFS(document.body.querySelector('.root'))
浏览器打印出来的结果如下:
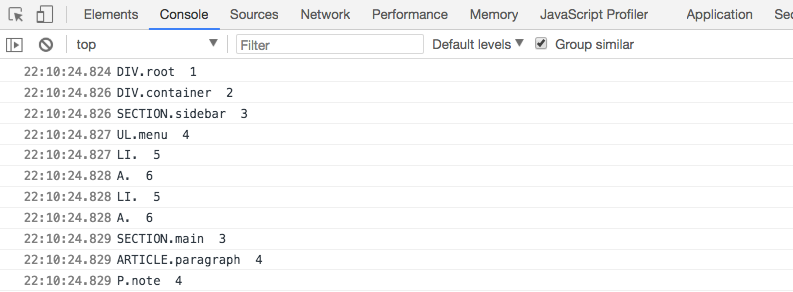
上面通过JavaScript使用了递归的方法实现了DFS,在控制台依次打印出节点的元素名,类名和层次。
深度优先可以理解为“一条路走到黑”,只有在撞到了“南墙”才回头。具体到DOM树中来说就是,从根节点开始,继而访问它的直接子元素,并依此往复直到不存在子元素。
再来看看对于DOM树的广度优先遍历的结果。广度优先可以理解为“一层一层的剥离”,对同一层次的元素全部遍历过后,再遍历下一层。广度优先适合使用队列这种数据结构来实现,将每层的节点依次放入队列,并根据队列“先入先出”的特性取出就可以了。在JavaScript中模拟队列的的方法可以使用数组方法的push和shift对应入队和出队操作。同样给出JavaScript实现的DOM树遍历。
对应的代码如下:
const BFS = (root) => {
if (!root) { return }
let queue = [{
item: root,
depth: 1
}]
while (queue.length) {
let node = queue.shift()
console.log(`${node.item.nodeName}.${node.item.classList} ${node.depth}`)
if (!node.item.children.length) {
continue;
}
Array.from(node.item.children).forEach((item, index, arr) => {
queue.push({
item: item,
depth: node.depth + 1
})
})
}
}
BFS(document.body.querySelector('.root'))
输出的结果如下:

有关于深度优先遍历和广度优先遍历更多的资料可以阅读:
假设你对深度优先遍历有了一定的了解。接下来回到querySelectorAll()和getElementsByTagName()世界中。使用这两个方法对DOM树进行遍历的思咱就是深度优先遍历算法,只不过节点对应着DOM树中的元素。
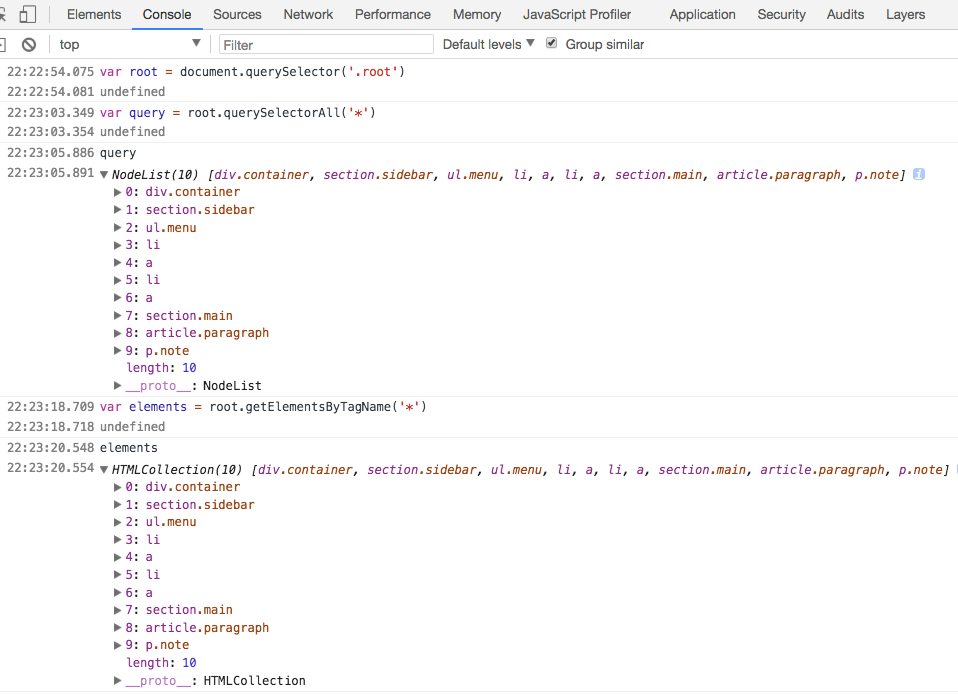
从图中的浏览器的控制台输出可以看出,两个方法返回的顺序都是一样的。返回的结果都是:
[
div.container,
section.sidebar,
ul.menu,
li,
a,
li,
a,
section.main,
article.paragraph,
p.note
]
返回值
querySelectorAll()的getElementsByTagName()两者的主要区别就是返回值。前者返回的是NodeList集合,后者返回的是HTMLCollection集合。其前者是一个静态集合,后者是一个动态集合。
其中动态集合和静态集合的最大区别在于:
动态集合指的就是元素集合会随着DOM树元素的增加而增加,减少而减少;静态集合则不会受DOM树元素变化的影响。
NodeList对象是一个节点的集合,是由Node.childNodes和document.querySelectorAll()返回的。NodeList并不是都是静态的,也就是说Node.childNodes返回的是动态的元素集合;querySelectorAll() 返回的是一个静态集合。
HTMLCollection 返回一个时时包括所有给定标签名称的元素的HTML集合,也就是动态集合。
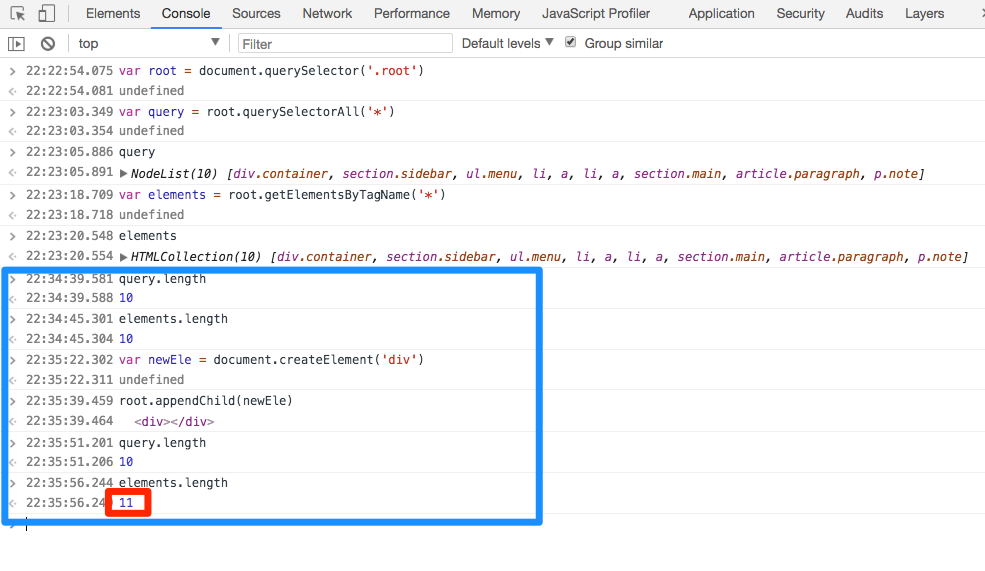
上图已经告诉我们结果了。虽然root.appendChild(newEle)增加了一个新的div。但query.length还是10,而elements.length却变成了11。
有关于这方面更详细的介绍,可以阅读上一篇《动态集合》文章。
为什么 getElementsByTagName 比 querySelectorAll 方法快?
通过上一节的学习,我们知道为什么动态NodeList要比静态NodeList更快。即:
使用
getElementsByTagName方法我们得到的结果就像是一个对象的索引,而通过querySelectorAll方法我们得到的是一个对象的克隆;所以当这个对象数据量非常大的时候,显然克隆这个对象所需要花费的时间是很长的。
这也就是为什么说getElementsByTagName()在所有浏览器上都比querySelectorAll()要快好多倍。
其中具体的原委早在2010年@Nicholas C. Zakas就做过相关的阐述,而且还提供了一份JSPerf测试页。
虽然道理明白了,但是希望自己动手撸一下代码,这样更能加强我们的理解。比如下面这样的一个测试用例:
let body = document.getElementsByTagName('body')[0]
for (let i = 0; i < 1000; i++) {
let divEle = document.createElement('div')
divEle.textContent = `item ${i + 1}`
body.appendChild(divEle)
}
console.time('getElementsByTagName: ')
let elements = document.getElementsByTagName('div')
console.timeEnd('getElementsByTagName: ')
console.time('querySelectorAll: ');
let query = document.querySelectorAll('div')
console.timeEnd('querySelectorAll: ')
当我们在body下创建1000个div标签时,控制台打印出来的结果如下:
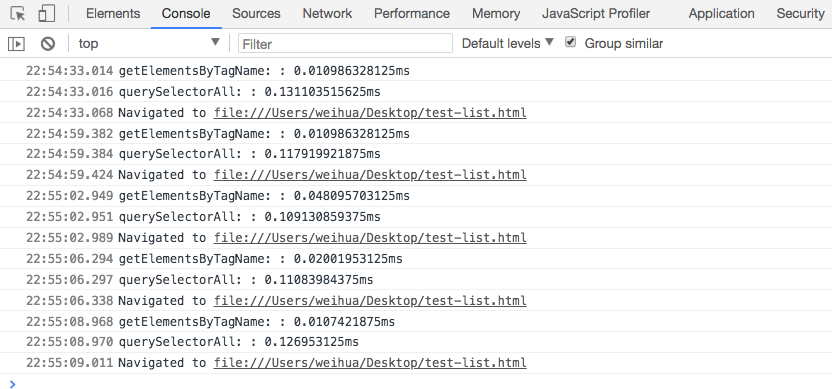
上面是刷新多次后的结果,接下来,把1000个换成1000000个,结果会是:
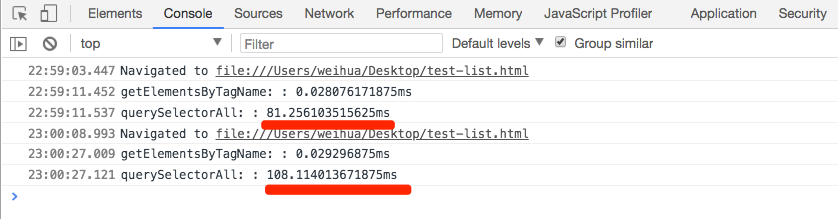
结果已经告诉我们了。当div数量增加时,使用querySelectorAll()方法所费的时间越来越长,而使用getElementsByTagName()方法所费的时间并没太大的差异。从而再次验证:getElementsByTagName()比querySelectorAll()要快好多倍。
还有一点其实是需要我们注意的,我们使用的console.time和console.timeEnd方法得出来的时间并不是特别准确的;更准确的做法是使用Performance这个对象提供的now方法来进行计时。这里有一些文章关于为什么要使用Performance的解释: Timing JavaScript Code with High Resolution Timestamps和Discovering the High Resolution Time API,接下来我们来修改一下上面的代码:
let body = document.getElementsByTagName('body')[0]
for (let i = 0; i < 10000000; i++) {
let divEle = document.createElement('div')
divEle.textContent = `item ${i + 1}`
body.appendChild(divEle)
}
let timeStart0 = window.performance.now();
let elements = document.getElementsByTagName('div');
let timeEnd0 = window.performance.now();
let timeStart1 = window.performance.now();
let query = document.querySelectorAll('div');
let timeEnd1 = window.performance.now();
console.log(`getElementsByTagName方法使用了: ${timeEnd0 - timeStart0} ms`);
console.log(`querySelectorAll方法使用了: ${timeEnd1 - timeStart1} ms`);
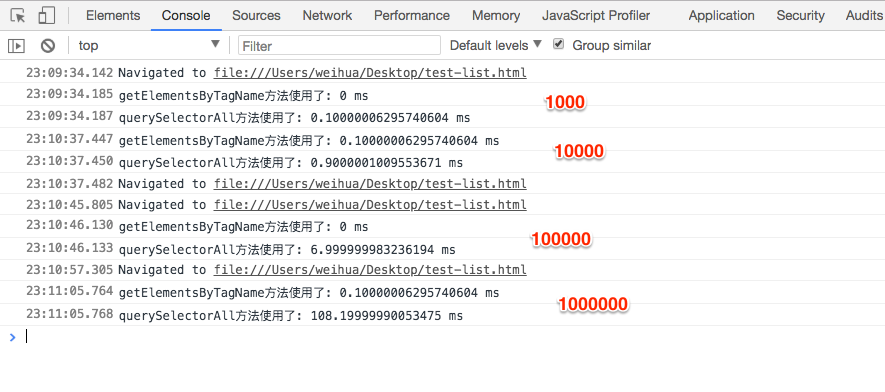
可以清楚地看到,随着div标签数量的增多,使用querySelectorAll方法会越来越慢,而使用getElementsByTagName方法的速度却变化不大,这也说明了getElementsByTagName方法确实比querySelectorAll方法要快。
这就是querySelectorAll和getElementsByTagName不同之处。所以以后在项目中使用的时候,还是需要注意。不然一不小心,就掉坑里了。

大漠
如需转载,烦请注明出处:https://www.fedev.cn/javascript/querySelectorAll-vs-getElementsByTagName.htmlnike air max 2019 zappos