CSS生成内容
在CSS中可以使用content来生成内容,该特性最早是在CSS2规范中引入的,经过多年的发展,现在该规范已经进入到了Level 3版本。在实际开发中,时常能看到开发人员在伪元素::before和::after中使用content为Web添加内容,只不过这些并不是DOM树中的一员,换句话说,可以在不调整HTML的情况下生成图标、图像、文本等。但很多开发人员可能只知道content添加一个值,事实上它有很多新的特性大家不太了解,接下来这篇文章我们就来和大家探讨这方面的知识。
什么是生成内容
从技术上讲,生成的内容是由CSS在文档树(DOM树)中创建的一个简单抽象(Abstraction)。因此,在实践中,生成的内容只存在于Web文档的布局中。
在Web构建中,最常见的示例就是用content来生成图标,比如Font Awesome就采用了这方面的技术:
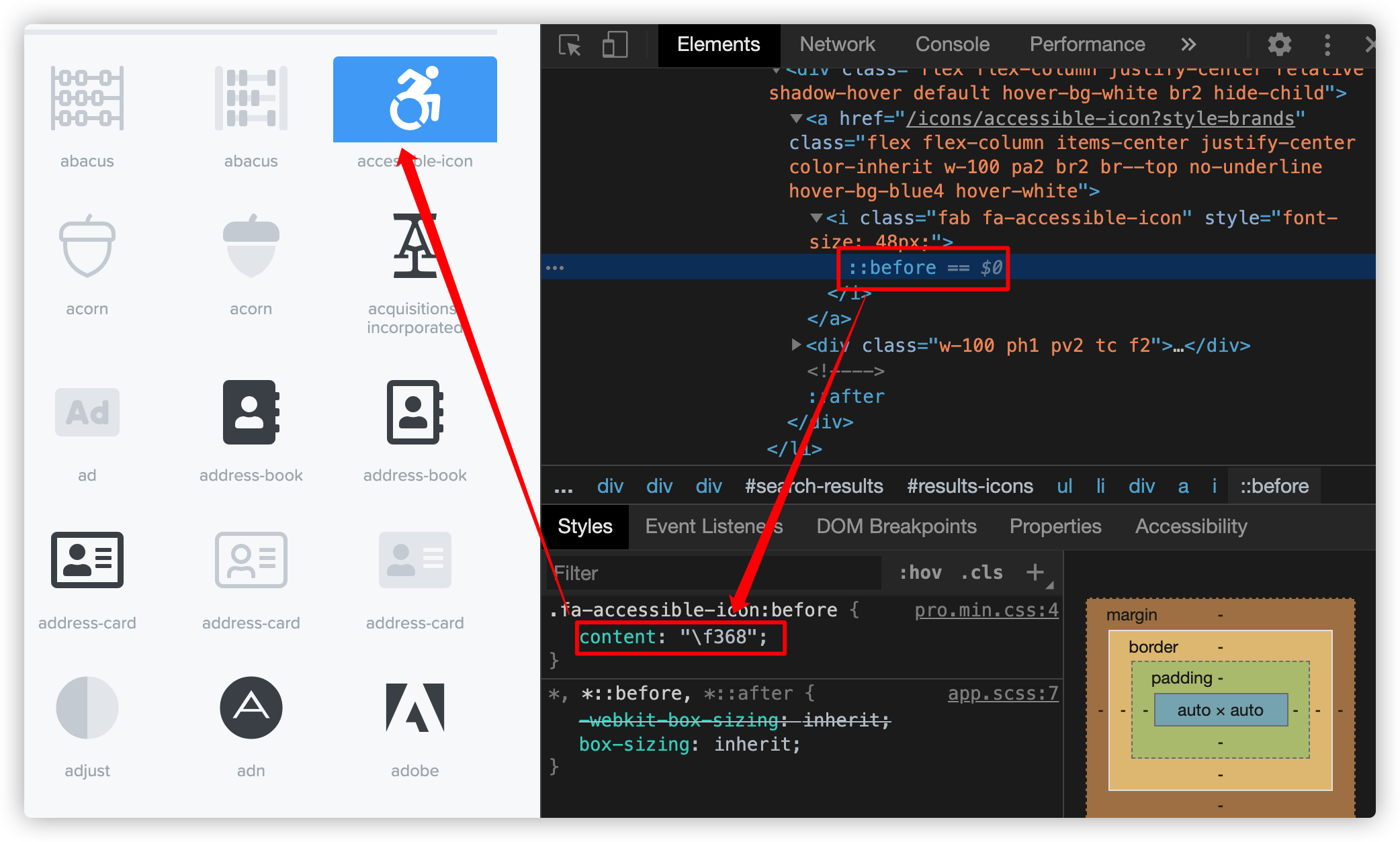
在content不仅仅是一个值、实际内容和一个替代文本,还可以像下面这样设置两个值:
.element::before {
content: "★" / "Highlighted item";
}
估计有不少朋友都不知道content还可以这样使用,甚至还有更多不知道的事情。为了让大家能更彻底的了解content,我们就先从其语法规则开始。
CSS的content语法规则
CSS的content属性用来指定在元素或伪元素中渲染的内容。具体的使用规则如下:
content: normal | none | [ <content-replacement> | <content-list> ] [/ [ <string> | <counter> ]+ ]?
如果content运用于元素上,它只有一个目的:指定元素正常渲染,或者用图像(可通常还有一些相关的alt文本)替换元素。
如果content运用于伪元素上,它更强大。它控制元素是否渲染,是否可以用图像替换元素,或者用任意内容(文本和图像)替换元素。
content取值不同,所起作用也略有不同。
normal
取值为normal时:
- 对于元素或外距盒(
margin-box),它的计算值是元素自身的内容 - 对于伪元素
::before或::after,它的计算值是none - 对于
::marker,它的计算值是其自身normal
none
在元素上,这将阻止将元素的子元素渲染为该元素的子元素,就好像该元素是空的一样。在伪元素上,它会阻止伪元素的创建,就好像设置了dislay: none一样。
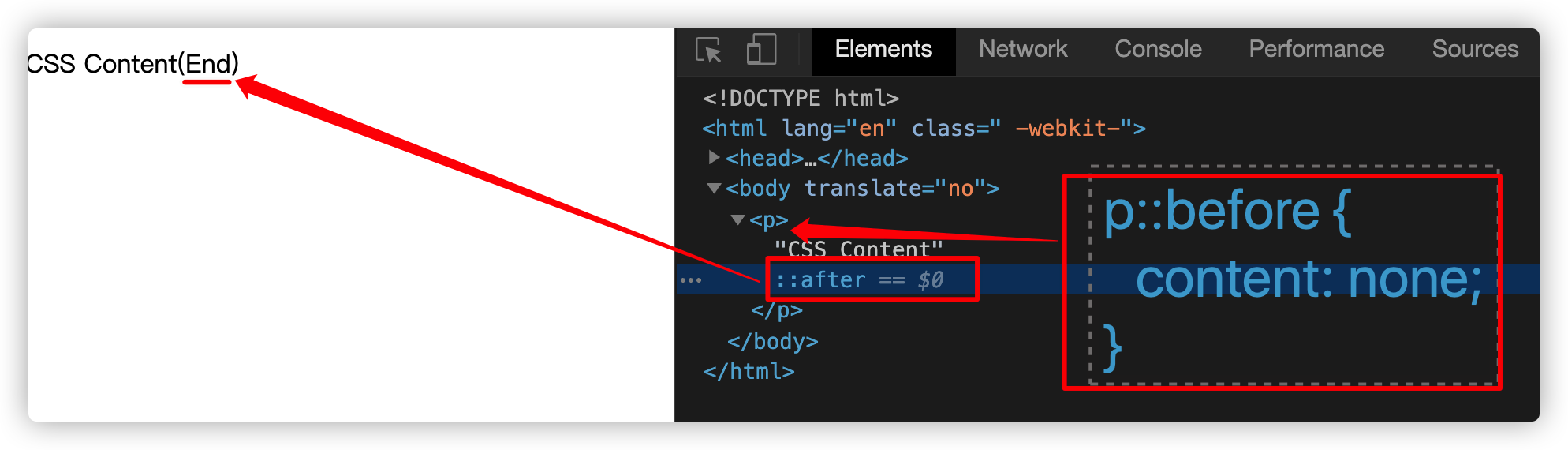
在这两种情况下,元素或伪元素不会生成任何内容。比如说,在伪元素上显式设置了content: none,那么该会就不会自动插入到DOM中,也不会生成任何内容:
p::before{
content: none
}
p::after {
content: '(End)'
}
<content-replacement>
相当于<image>。
它会使元素或伪元素成为可替换的元素,用指定的<image>填充。它的正常内容被抑制且不生成盒子,类似于设置了display: none。
如果<image>是一个无效的图像,那么它必须被处理为表示一个内部宽度和高度为0的图像,并且会填充一个透明黑色。
<content-list>
相当于:
[ <string> | contents | <image> | <counter> | <quote> | <target> | <leader()> ]+
将元素的内容替换为一个或多个与指定值对应的匿名内联框,按指定的顺序。它的正常内容被抑制并且不产生盒子,好像display: none。
每个值都向元素的内容贡献一个内联框。对于<image>,这是一个内联匿名替换元素;对于其他的,它是一个匿名的内联文本。
如果<image>表示一个无效的映像,用户代理必须执行以下操作之一:
- 跳过
<image>,不为它生成任何东西 - 显示一些图像的指示,比如”损坏的图像“图标
/ [ <string> | <counter> ]+
为元素指定可替换文本。如果省略,该元素则没有指定可替换文本。
仅从语法上来看,太过于空洞,接下来我们主要围绕<content-list>的值和函数来和大家展开。
<content-list>值和函数
<content-list>值在content中来生成一个或多个匿名内联框填充元素,包括图像、字符串、计数器的值和元素的文本值。在接下来的内容中来列举这方面的各种可能性。
先来看使用content常做的事情。
通过CSS的伪元素向另一个元素添加一个元素的示例很多,但这有一个重要的前提,那就是content的值不能是none和normal,因为取这两个值不会创建伪元素。也就是说,我们在::before或::after的content传其它值都可以向另一个元素添加一个元素,并且还可以设置相关的样式,达到一些设计上的需要。比如构建一个提示框:
<!-- HTML -->
<span class="tooltip-toggle" aria-label="Sample text for your tooltip!" tabindex="0">
// CSS
.tooltip-toggle {
cursor: pointer;
position: relative;
&::before,
&::after {
color: #efefef;
opacity: 0;
pointer-events: none;
text-align: center;
position: absolute;
}
&::before {
top: -80px;
left: -80px;
background-color: #2B222A;
border-radius: 5px;
color: #fff;
content: attr(aria-label);
padding: 1rem;
text-transform: none;
transition: all 0.5s ease;
width: 160px;
}
&::after {
top: -12px;
left: 9px;
border-left: 5px solid transparent;
border-right: 5px solid transparent;
border-top: 5px solid #2B222A;
content: " ";
margin-left: -5px;
width: 0;
}
&:focus::before,
&:focus::after,
&:hover::before,
&:hover::after {
opacity: 1;
transition: all 0.75s ease;
}
}
效果如下:
另一个示例就是打印Web页面的时候打印出链接地址。大家都知道,用户点击Web文档中的超链接可以跳转到指定的页面,但如果在打印Web页面时,如果未输出对应的链接地址,那么链接就没啥用了。所以在编写CSS样式时,通常在打印样式中使用content和attr()函数的组合,将链接地址放在超链接边上,一起打印出来:
@media print {
a[href^="http://"]::after,
a[href^="https://"]::after {
content: " (" attr(href) ")";
}
}
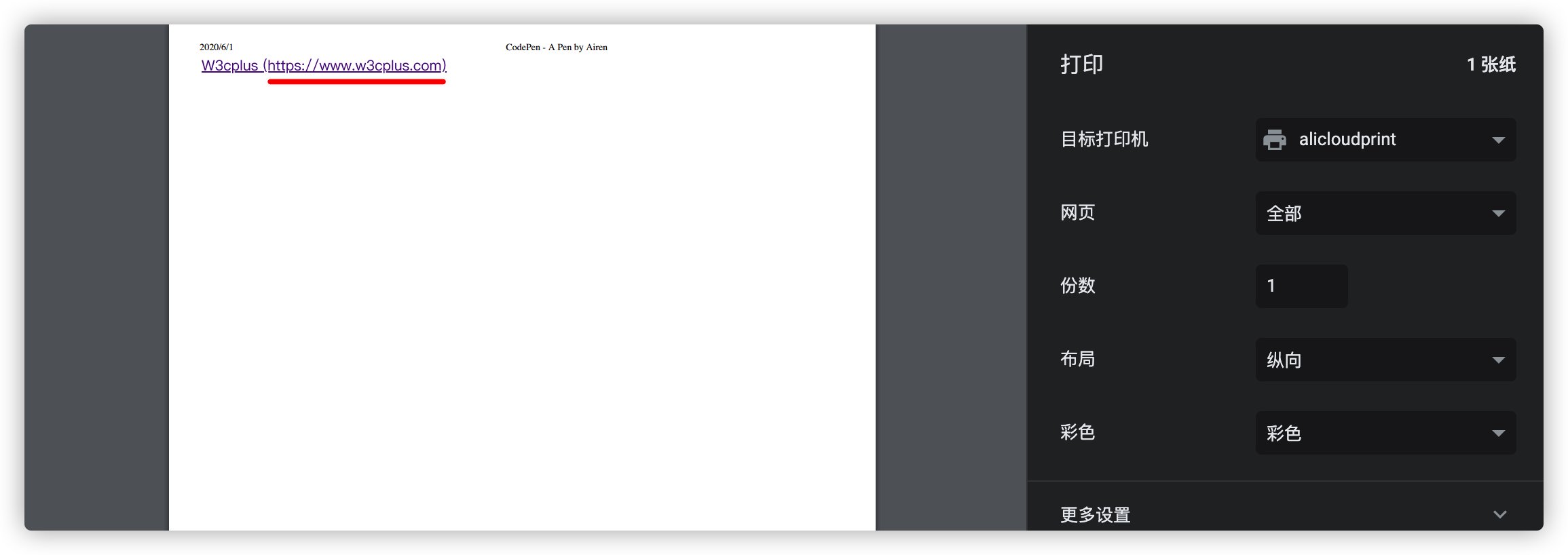
另外一个示例就是,在Web构建中需要自定义一些计数器效果:

我们就可以使用content、counter-reset、counter-increment和::before组合在一起,来构建:
.card {
counter-increment: count;
&::before {
content: counter(count, decimal-leading-zero);
}
}
从上面这几个常用的示例中可以看出来,我们在content中插入的值有字符串,比如"("和")",也有attr()引入HTML的元素的属性值,比如attr(href),也有counter()函数引入counter-increment声明的值,比如counter(count, decimal-leading-zero)。这些值对应的是<content-list>中的<string>、<counter>等。接下来,我们具体来看<content-list>中的值和函数的使用和细节。
<string>
给content指定字符串,将会生成一个匿名的内联框。给content指定的字符串可以是任意有效的字符串,比如空格符 ,普通的文本字符串,Emoji,以及一些特殊字符,比如HTML的实体符。
给content指定字符串值时,一般会用单引号或双引号括起来,比如:
li::before {
content: "梦开始的地方";
}
li::before {
content: "\2713";
}
在使用content插入HTML实体符号,可以直接将HTML的实体符当作字符串给content:
.element::before {
content: '★'
}
也可以通过下面的工具,将HTML实体符转换成能用于CSS的十六进制:
比如上面的★转换出来的CSS值就是\2605:
.element::before {
content: '\2605'
}
正如前面提到的,很多IconFont都采用的是这种方案,在content传递的是Icon对应的特殊字符串,只不过经过编码,更适用于CSS。
在给content传字符串时可以同时传多个字符串,比如:
li::before {
content: "(" "\2605" ")";
}
你会发现,渲染出来是(★)。你可能发现了,即使你在多个字符串之间留有空格,但它们会合并。如果你在引入的字符串中有多个空格符,比如下面这个示例:
li::before {
content: '第一章: ' ' ...'
}
渲染出来的结果会将多个空格字符合并成一个,结果是会这样第一章: ...。
<image>
给content传<image>值是指使用url()引入一张图像或CSS渐变。这个时候创建了一个内联可替换元素。比如:
li::before {
content: url('https://s3-us-west-2.amazonaws.com/s.cdpn.io/144736/marker-icon.png');
}
li::before {
content: linear-gradient(to right, #f36, #90f);
}
正如上面示例所示,该方式给content传的<image>值有点类似于background-image属性。但没有类似background-size这样的属性来控制<image>的大小。
如果<image>是个无效的图像,那么这个值什么都不表示,就好像content中没设置值一样。
body::before {
content: url('https://w#.png')
}
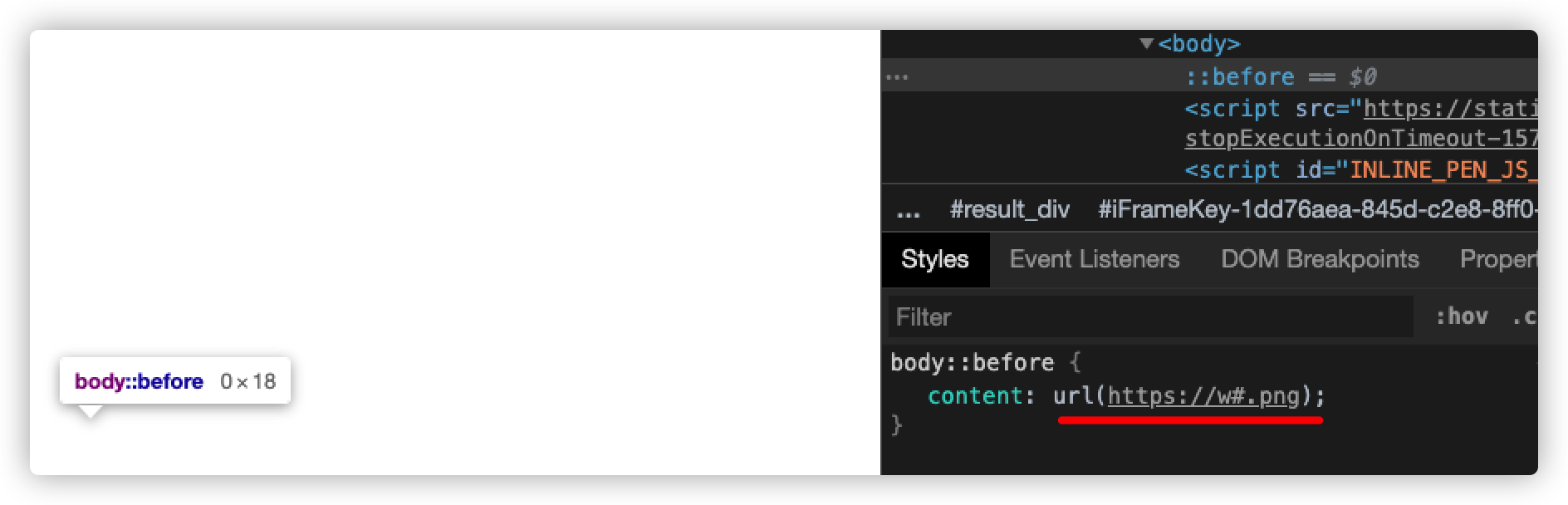
事实上,给content传<image>值平时使用较少,很多同学更喜欢给content传一个空字符串,然后通过给相应的伪元素设置background相关的属性,来达到引入图片的效果,比如下面两个示例,最终效果是一致的:
body::before,
body::after {
display: inline-flex;
width: 10vh;
height: 10vh;
margin: 2vh;
border: 2px solid blue;
border-radius: 5px;
}
body::before {
content: linear-gradient(to right, #f36, #90f);
}
body::after {
content: '';
background: linear-gradient(to right, #f36, #90f);
}
当你拖动浏览器改变视窗大小时,你会发现::before(即直接给content传<image>)不会随着容器变化而变化,需要自动刷新一次才能正常填充:
另外,content引入<image>时,对应伪元素部分样式看上去未生效,比如下面这个示例,添加一个圆角,结果效果看上去并未运用上:
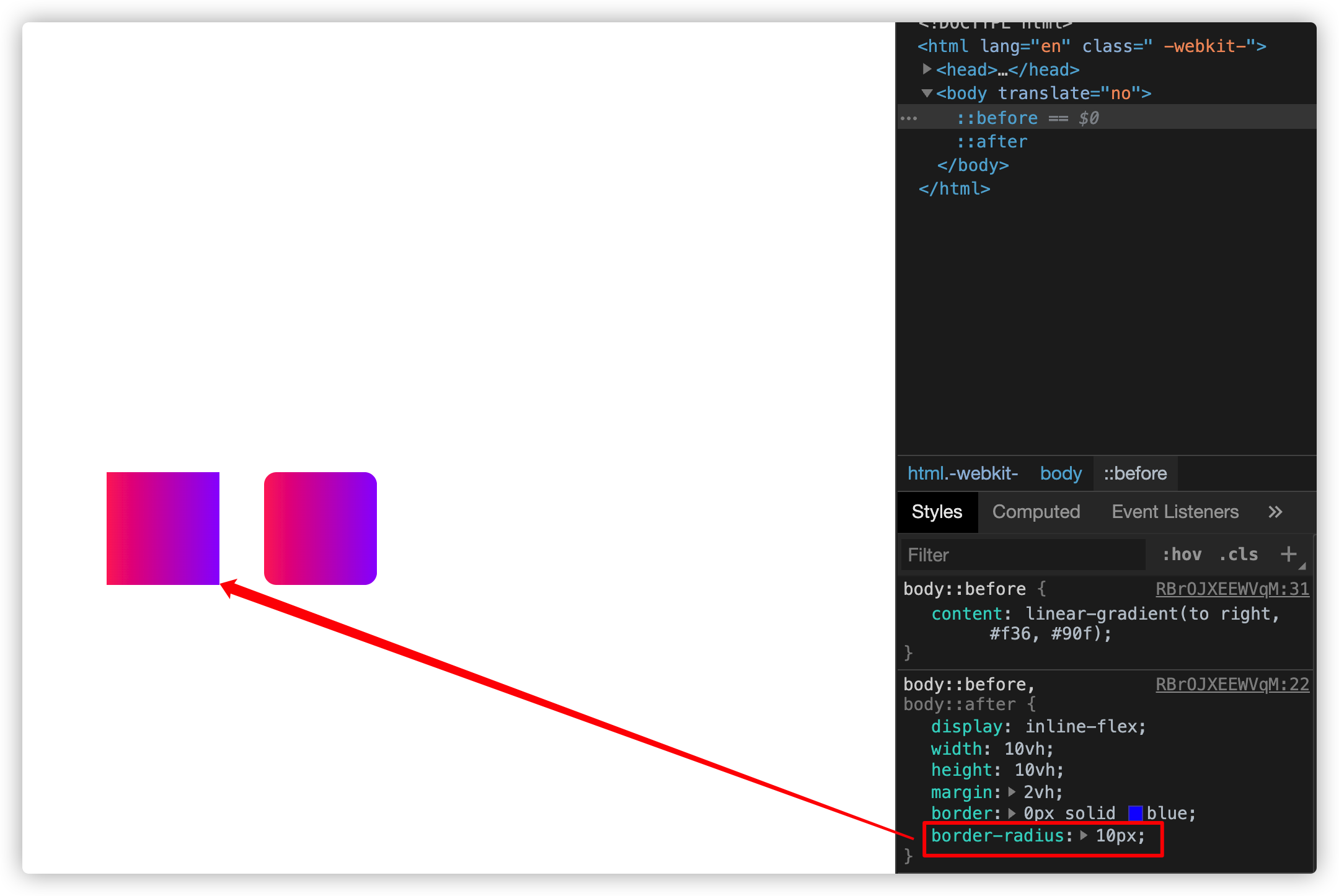
特别声明:为什么会有这样的现象,我也没有查看相关资料,如果你在这方面有经验,欢迎在下面的评论中分享!
<quote>
当我们在HTML中使用<blockquote>、<q>和<cite>时涉及到引号的使用。这几个标签元素基于不同的语言,引号的使用会有不同的样式。

而样式上的处理可以将quotes和content的各种*-quote值结合起来使用,从而正确地使用这些引号的样式。其中quotes属性可以接受的值:
quotes: auto | none | [<string><string>]+
每个值的具体含义是:
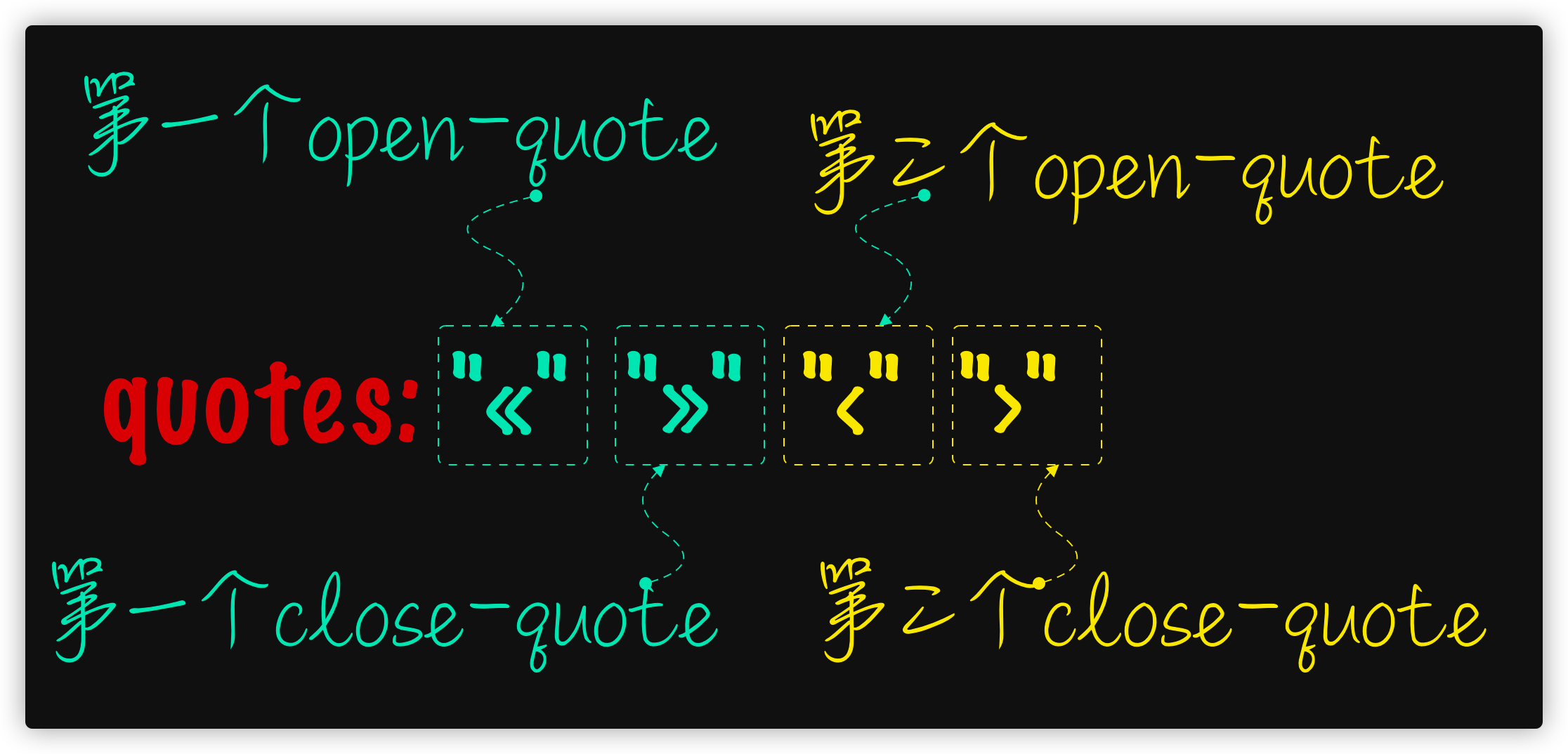
none:content属性的open-quote和close-quote不产生引号标记,就好像content设置了no-open-quote和no-close-quoteauto:基于元素或其父元素的lang,客户端会自动选择适合于印刷的引号(quotes的值)[ <string> <string> ]+:content属性的open-quote和close-quote取值来自于这个引号列表。第一对(最左)表示引用的最外层,第二对表示嵌入的第一层,等等。用户代理必须根据嵌入的级别应用适当的一对引号
我们回到content中引入的<quote>,其对应的值有:
<quote> = open-quote | close-quote | no-open-quote | no-close-quote
open-quote和close-quote:这些值将由quotes属性中的适当字符串替换,并增加(减少)引号的嵌套级别no-open-quote和no-close-quote:不插入任何内容,即没有任何引号
我们来看一个简单的示例,
blockquote p::before {
content: open-quote;
}
blockquote p::after {
content: no-close-quote;
}
blockquote p:last-child::after {
content: close-quote;
}
不同的lang,引号的效果也不同:
再来看一个示例:
:lang(fr) > * {
quotes: "\00AB\2005" "\2005\00BB" "\2039\2005" "\2005\203A"
}
:lang(en) > * {
quotes: "\201C" "\201D" "\2018" "\2019"
}
// 等同于
:lang(fr) > * {
quotes: "« " " »" "‹ " " ›"
}
:lang(en) > * {
quotes: "“" "”" "‘" "’"
}
示例中设置了quotes属性,以便在所有封印经上正确地使用open-quote和close-quote。但上面代码只适用于包含英语、法语或同时包含这两种语言的Web文档。如果不是这两语言,那么客户端会自动来匹配:
在这个示例中,quotes指定了两对引号样式:
当你在元素中引用方式有嵌套关系时,就能分层次的使用引号样式:
<!-- HTML -->
<p><q>Trøndere gråter når <q>Vinsjan på kaia</q> blir deklamert.</q></p>
<p lang="zh-CN"><q>我想说<q>梦开始的地方</q> 在这里。</q></p>
// CSS
:lang(en) > q {
quotes: '"' '"' "'" "'"
}
:lang(zh-CN) > q {
quotes: "«" "»" "’" "’"
}
q::before {
content: open-quote
}
q::after {
content: close-quote
}
效果如下:

其他
就目前为止,content还支持attr()函数引入HTML元素的属性值,比如文章开头的Tooltips示例,另外还支持<counter>(即counter-reset、counter-increment和counter())实现自定义计数器。
除此之外,到目前为止还没有得到浏览器支持的有contents、<target>、<leader()>等。如果这几个值得到浏览器的支持,可以帮助我们实现很多有意思的效果,比如leader()就可以帮助我们轻易的实现书本大纲的效果:
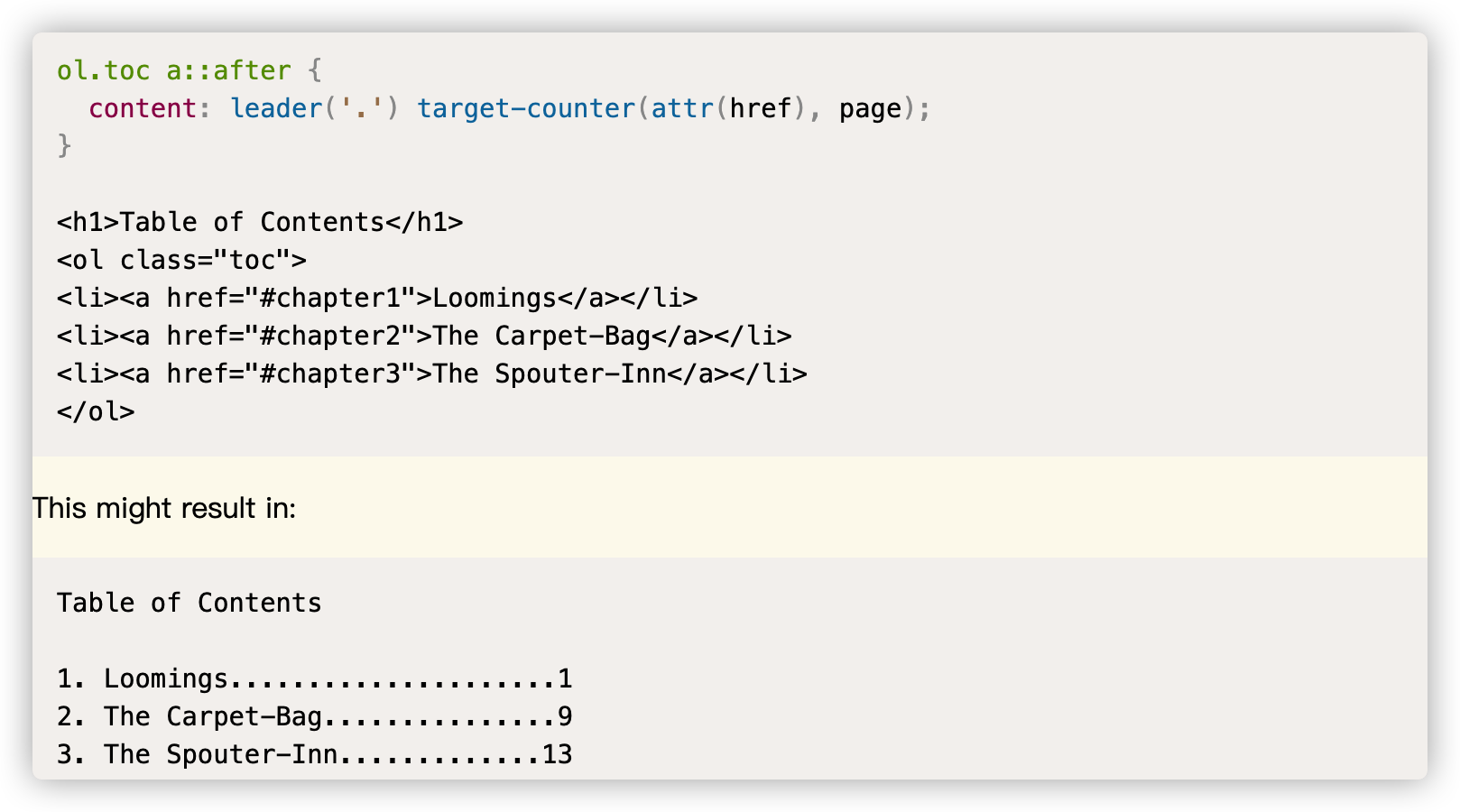
其他的这里就不发过多时间和大家探讨了,因为目前还没有任何浏览器支持,而且就这部分而言,虽然被纳入到了规范当中,但并不代表未来不会有变化。
可访问性
在上面的示例中,我们看到的示例都有一个共性,就是在content只接受一个属性值。事实上,它还可以接受另一个值(第二个值),该值和前一个值用 / 来分隔。这样做主要是为了给生成的内容提供可访问性。也就是说,CSS的content生成的内容也应该提供相应的Web可访问性,即生成的内容应该可搜索、可选择和屏幕阅读器能识别到。
我们来看一个简单的示例:
<!-- HTML -->
<a href="#">Go to favorites</a>
// CSS
a::before {
content: "★";
}
这个时候,读屏幕器(比如iOS voiceover,即旁白)会读出黑色星星 Go to favorites link:
这种体验其实并不太好。不过幸运的是,现在可以在content使用可替换文本。即前面提到的/后面的第二个值。这样一来,上面的示例就可以修改成:
a::before {
content: "★" / "Highlighted item";
}
或者
a::before {
content: "★" / "";
}
这个时候,屏幕阅读器就会把可替代文本内容读出来。屏幕阅读器会读出Highlighted item Go to favorites link。
同样的,content属性的第二个值(/后面的那个值)也可以使用attr()来引用DOM元素中的属性值做为可替换文本:
a::before {
content: "★" / attr(data-star-alt);
}
目前仅Chrome浏览器支持content: '' / ''这样的模式。在CSS中,和其他新特性类似,我们可以@supports来做判断。
@supports (content: "x" / "y") {
a::before {
content: "★" / "Highlighted Text";
}
}
@supports not (content: "x" / "y") {
a::before {
content: "★";
alt: "Highlighted Text";
}
}
比如上面的示例,在支持的浏览器(比如Chrome浏览器)中Highlighted Text就会作为★实体符的可替换文本,屏幕阅读器将会朗读这个可替换文本;对于不支持的浏览器(比如Safari浏览器),它虽不识别content属性中的第二个值,但可以识别alt的值,能达到相似的效果。
小结
正如文章所述,在Web页面或应用开发的时候,很多开发者为了尽可能的避免添加额外的DOM结构,在一些场景之下会通过::before或::after伪元素来给元素添加子元素(向一个元素中插入元素),这个时候不能缺少content(哪怕给content传一个空格符)。除此之外,还能实现一些其他的效果,比如Tooltips效果,自定义计数器,动效,图标等。除了这些,可能还有很多我并没有想到的作用,如果你在这方面有经验,欢迎在下面的评论中与我一起分享。