Virtual DOM 的内部工作原理
**特别声明:**本文转载@ludafa翻译@rajaraodv的《The Inner Workings Of Virtual DOM》一文,如需转载,烦请注明原文出处:http://efe.baidu.com/blog/the-inner-workings-of-virtual-dom/
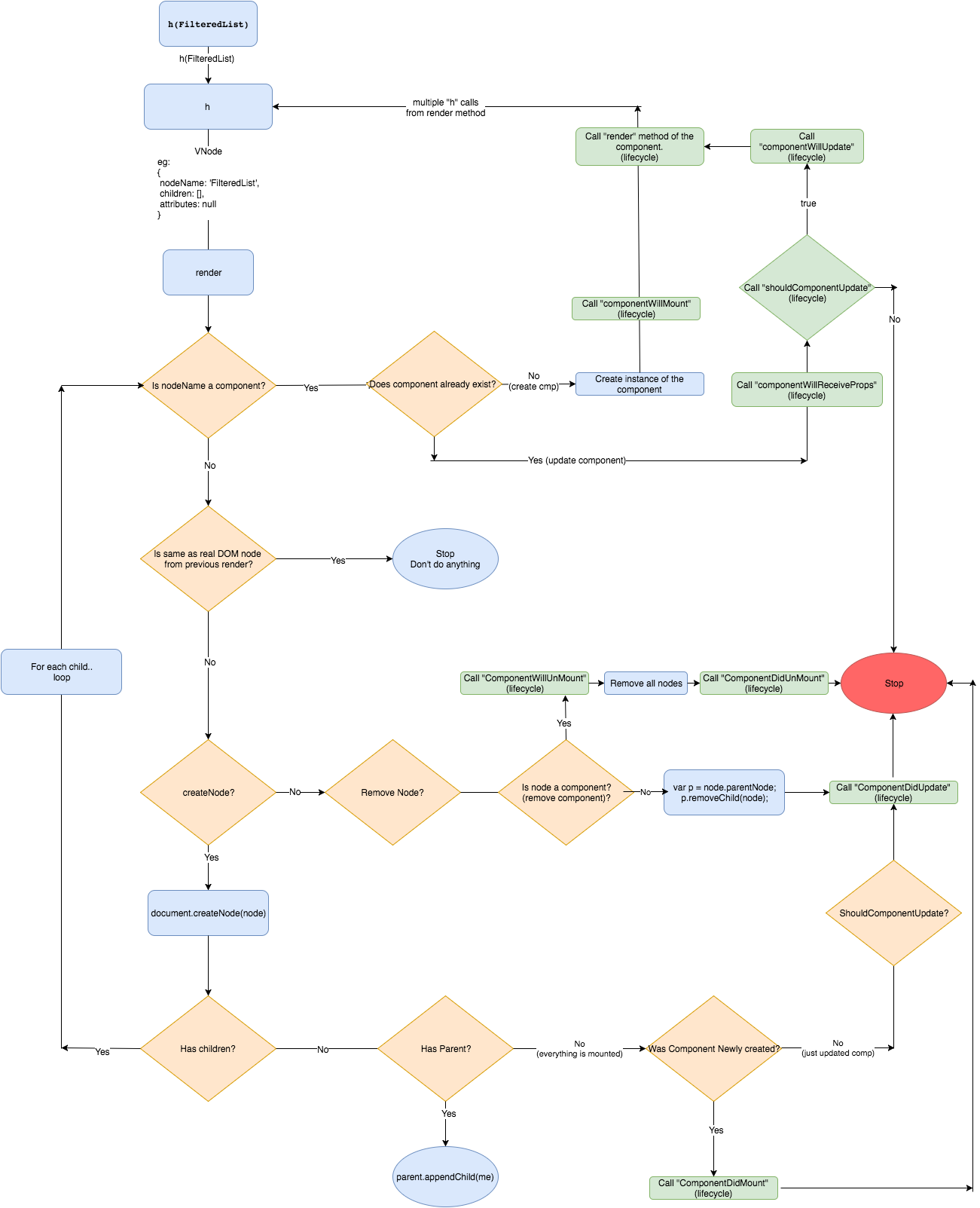
Preact VDOM 工作流程图
虚拟DOM (VDOM,也称为 VNode) 是非常神奇的,同时也是复杂难懂的。 React,Preact 以及其他类似的 JS 库都使用了虚拟 DOM 技术作为内核。可惜我找不到任何靠谱的文章或者文档可以简单又清楚解释清虚拟DOM的内部细节。所以,我就想到自己动手写一篇。
**注:**这是一篇很长的博客。为了让内容更容易理解,我添加了很多图片。这也导致这篇博客看上去更长了。
在这篇博客中,我是基于 Preact 的代码和 VDOM 机制来介绍的。因为 Preact 代码量更少,你在以后也可以不费力地自己看看源码。但是我觉得绝大部分的概念也同样适用于 React。
我希望读者通过这篇博客可以更好地理解虚拟DOM,并期待你们可以为 React 和 Preact 等开源项目提供贡献。
在这篇博客中,我会通过一个简单的例子来仔细地介绍虚拟DOM的每个场景,给大家虚拟DOM是如何工作的。特别地,我会介绍以下内容:
- Babel 和 JSX
- 创建 VNode – 单个虚拟 DOM 元素
- 处理组件和子组件
- 初始渲染和创建 DOM 元素
- 再次渲染
- 删除 DOM 元素
- 替换 DOM 元素
演示程序
演示程序是一个简单的可筛选的搜索程序,包含了两个组件 FilteredList 和 List。List 组件会渲染一个城市列表(默认情况是 California 和 New York)。示例还有一个搜索框,可以根据搜索框的输入内容来筛选列表。十分直接了当。
概览
首先,我们用 JSX(html in js)来编写组件。我们会使用 Babel 将组件转译成纯 JS 。接着 Preact 的 h hyperscript 函数会将组件再转化成 VDOM 树(也就是 VNode)。最终, Preact 的虚拟 DOM 算法,按照 VDOM 生成真实的 DOM 元素,完成我们的应用。
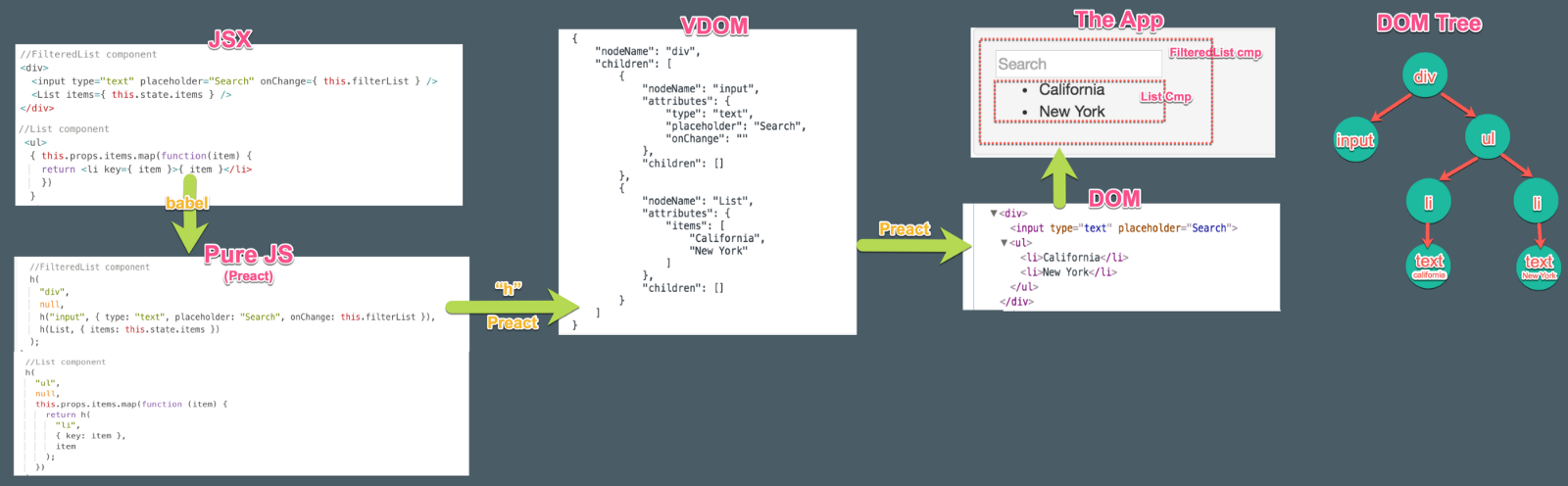
在我们深入 VDOM 生命周期的细节之前,先来理解一下 JSX;它提供了整个框架的起点。
Babel 和 JSX
在 React、Preact 以及类似的框架中,并没有 HTML;取而代之,所有都是 JS。所以我们甚至需要在 JavaScript 中来编写 HTML。但是,只用纯 JS 来写 DOM 简直就是恶梦!
拿我们的演示程序来说,我们必须这样写 HTML:
我一会儿来再解释
h
// FilteredList 组件
h (
'div',
null,
h('input', {
type: 'text',
placeholder: 'Search',
onChange: this.filterList
}),
h(List, {
items: this.state.items
})
);
// List组件
h(
'ul',
null,
this.props.items.map(function (item){
return h (
'li',
{key: item},
item
);
})
)
这就是我们需要引入 JSX 的原因。本质上来说,JSX 就是让我们愉快地在 JS 中写 HTML!同时,也允许我们在花括号里 {} 使用 JS。
如下所示,JSX 可以帮助我们很容易地编写组件:
// FilteredList 组件
<div>
<input type="text" placeholder="Search" onChange={ this.filterList } />
<List items={ this.state.items } />
</div>
// List组件
<ul>
{
this.props.items.map(function(item){
return <li key={ item }>{ item }</li>
})
}
</ul>
JSX 树转化为 JavaScript
JSX 很酷,但是它不是可用的 JS,而最终我们需要真实的 DOM。JSX 只能帮助我们简洁地表达真实 DOM,没有办法再完成其他的事情。
所以我们需要一个方法来把 JSX 转化成对应的 JSON 对象(VDOM,同时它也是一棵树)。只有这样我们最终才能使用它作为输入来创建真实 DOM。我们需要一个函数来实现它。
在 Preact 中,这个函数就是 h 函数。它与 React 中的 React.createElement是等效的。
h代表着 hyperscript —— 最先开始在 JS 中编写 HTML 的框架之一。
但如何把 JSX 转化成 h函数呢?这就是引入 Babel 的原因了。Babel 会找到所有的 JSX 结点并把它们转化成h函数调用。
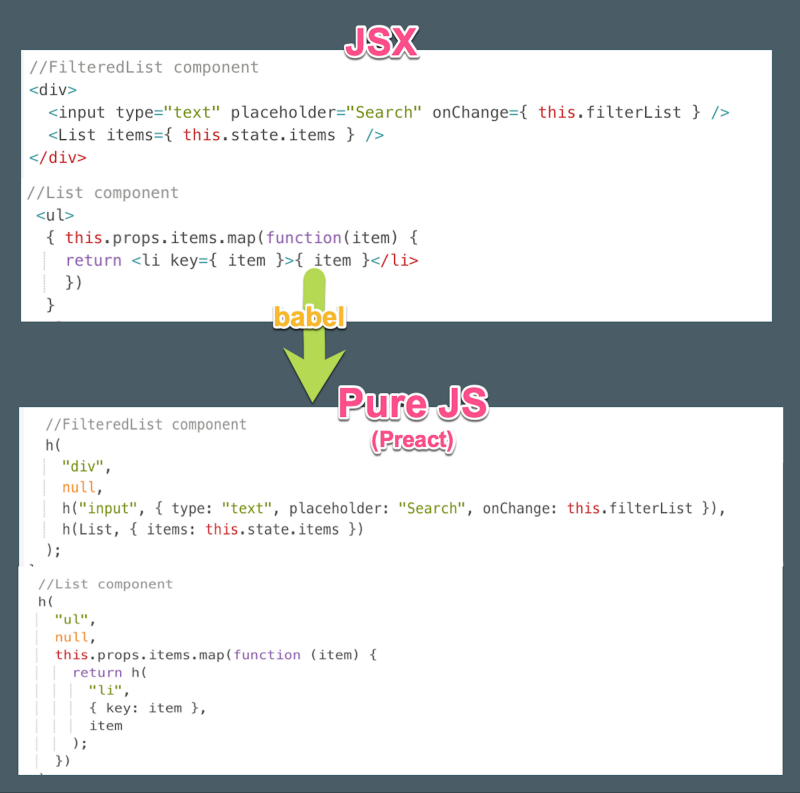
Babel JSX (React vs Preact)
默认条件下,Babel 会把 JSX 转译成 React.createElement 调用,因为它默认就是支持的 React。

左边是 JSX,右边是转译成 React 版的 JS
但我们可以通过添加Babel Pragma参数,很容易地把这个函数名换成任何我们想要的,比如 Preact 使用的 h:
Option 1:
// .babelrc
{
"plugins": [
[
"transform-react-jsx", {"pragma": "h"}
]
]
}
Option 2:
// 在每个 JSX 文件的第一行添加这一行注释
/** @jsx h*/

使用 Babel Pragma 来指定 h 函数
挂载到真实 DOM 的主入口
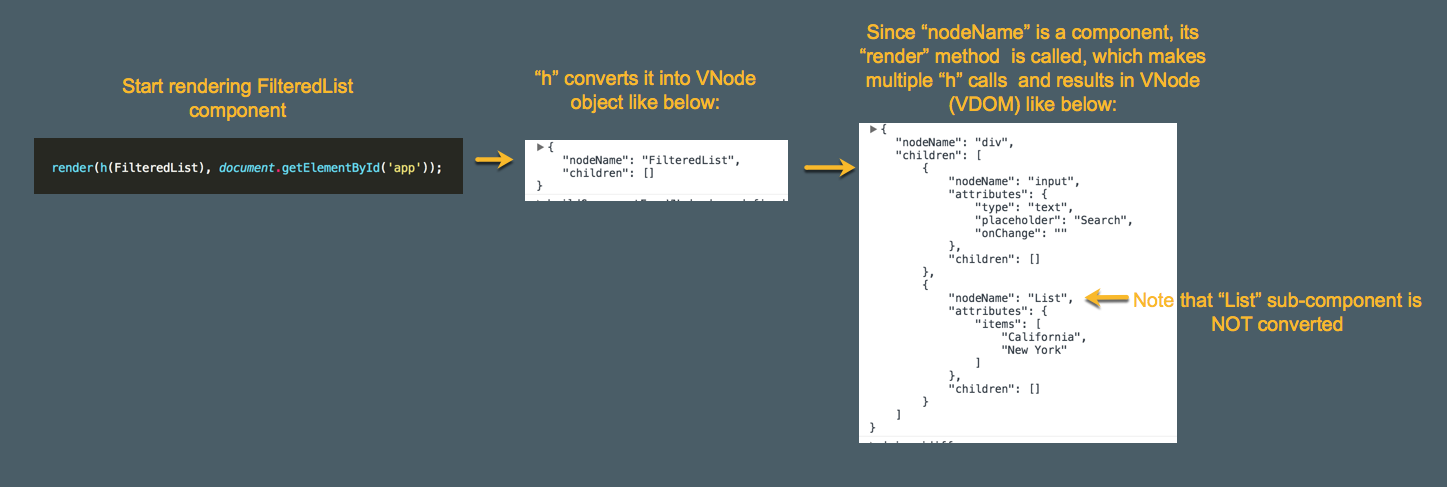
不仅是在组件的render函数中的代码需要被转译成h函数,初始的挂载入口也需要。
这就是开始执行的位置,一切的开始!
// Mount to real DOM
render(<FilteredList/>, document.getElementById(‘app’));
// Converted to "h":
render(h(FilteredList), document.getElementById(‘app’));
h函数的返回值
h函数使用 JSX 的返回值作为参数,创建了一个叫VNode的东西(React 的createElement创建 ReactElement)。一个 Preact 的VNode(或者是 React 的 Element)只是一个 JS 对象,代表着一个 DOM 结点,其中包含了它的属性和子结点。
VNode 大概是这样的:
{
nodeName: '',
attributes: {},
children: []
}
举个例子,我的演示程序中搜索框 Input 的 VNode 应该是这样的:
{
nodeName: 'input',
attributes: {
type: 'text',
placeholder: 'Search',
onChange: ''
},
children: []
}
h函数不会创建整个树!它只会为指定的结点创建一个 JS 对象。但由于render方法已经得到了树结构的 DOM JSX,最终产出的结果就会是一个带有子结点、孙结点的 VNode,看上去就是一棵树。
相关的代码
h: https://github.com/developit/preact/blob/master/src/h.jsVNode: https://github.com/developit/preact/blob/master/src/vnode.jsrender: https://github.com/developit/preact/blob/master/src/render.jsbuildComponentFromVNode:https://github.com/developit/preact/blob/master/src/vdom/diff.js#L102
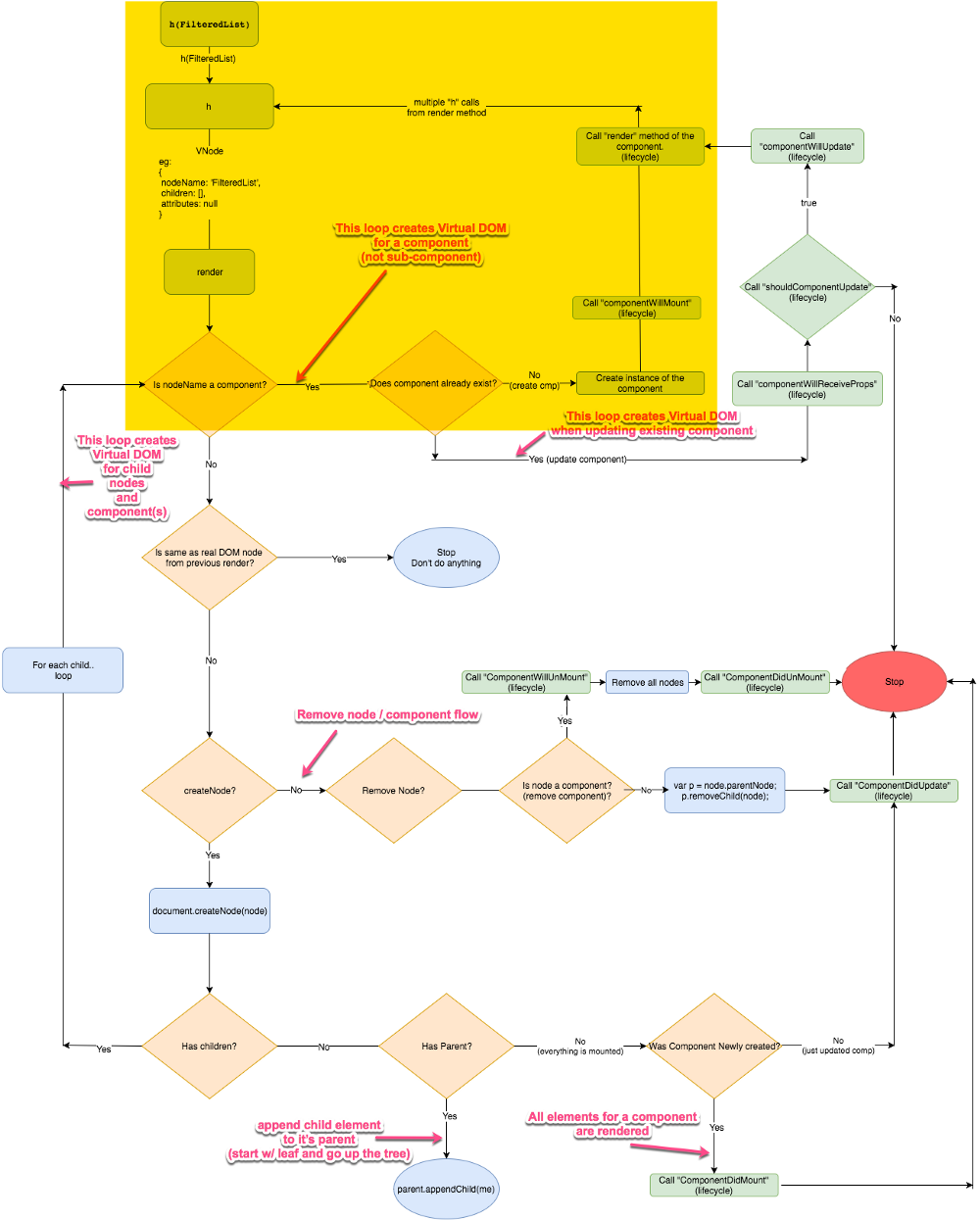
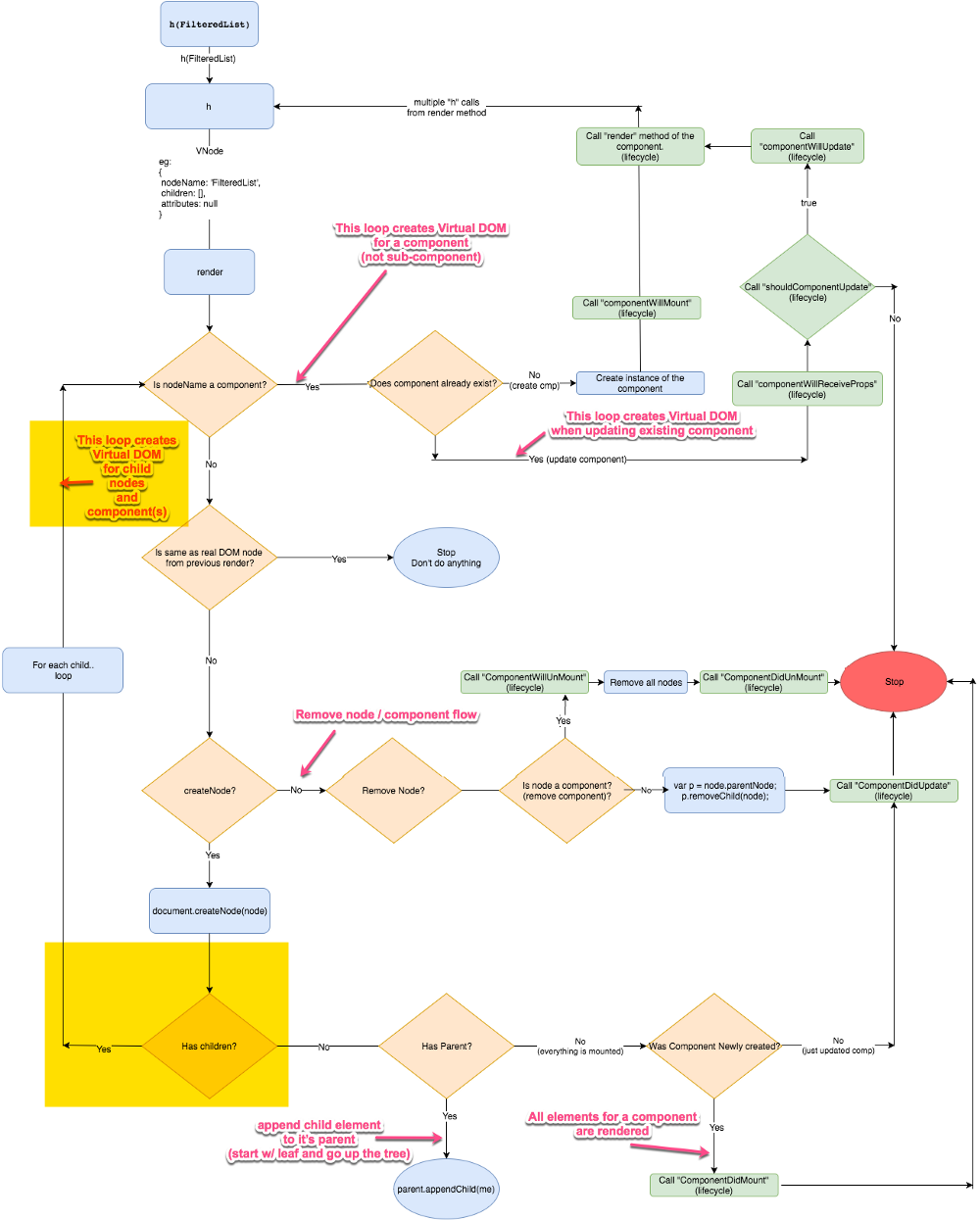
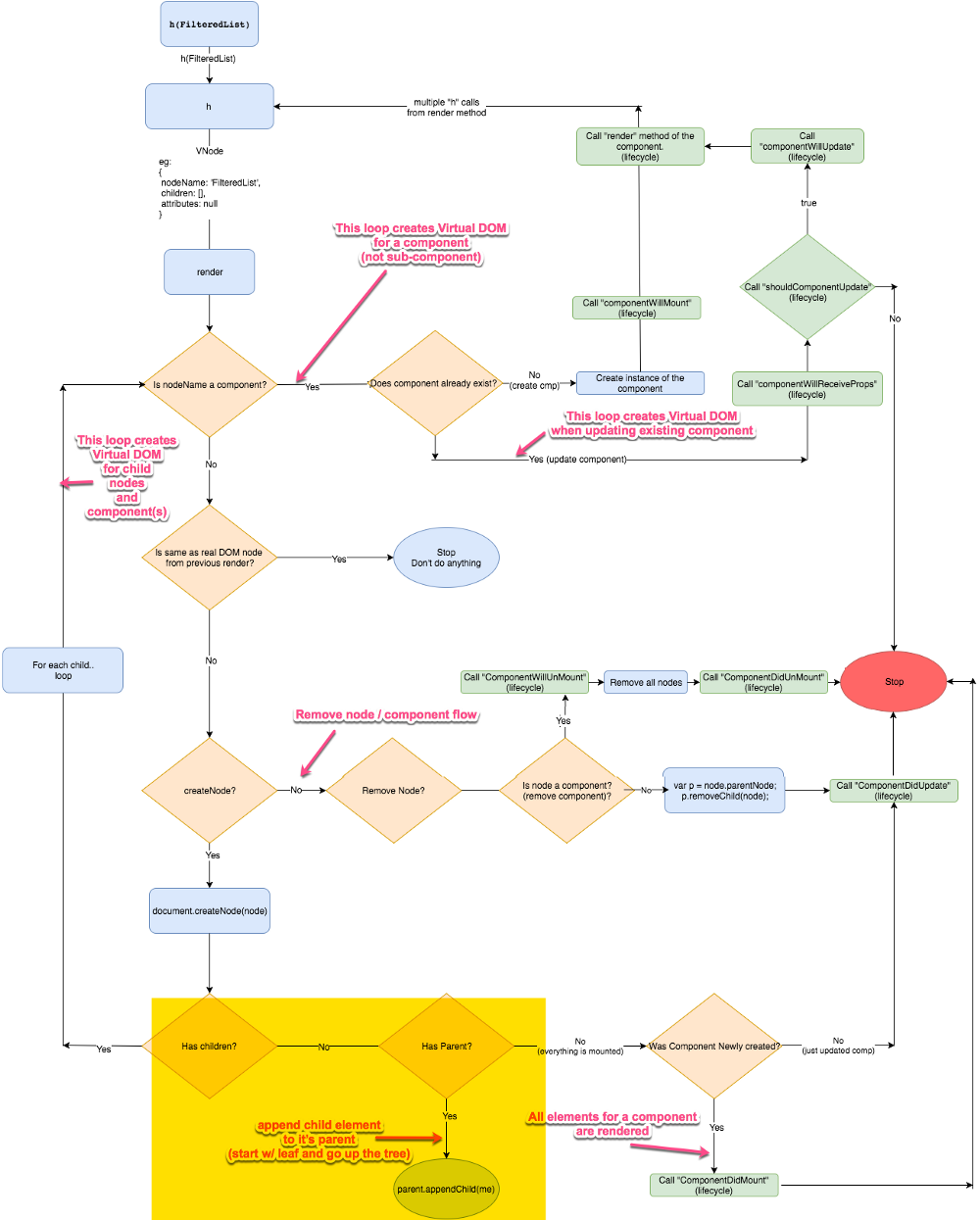
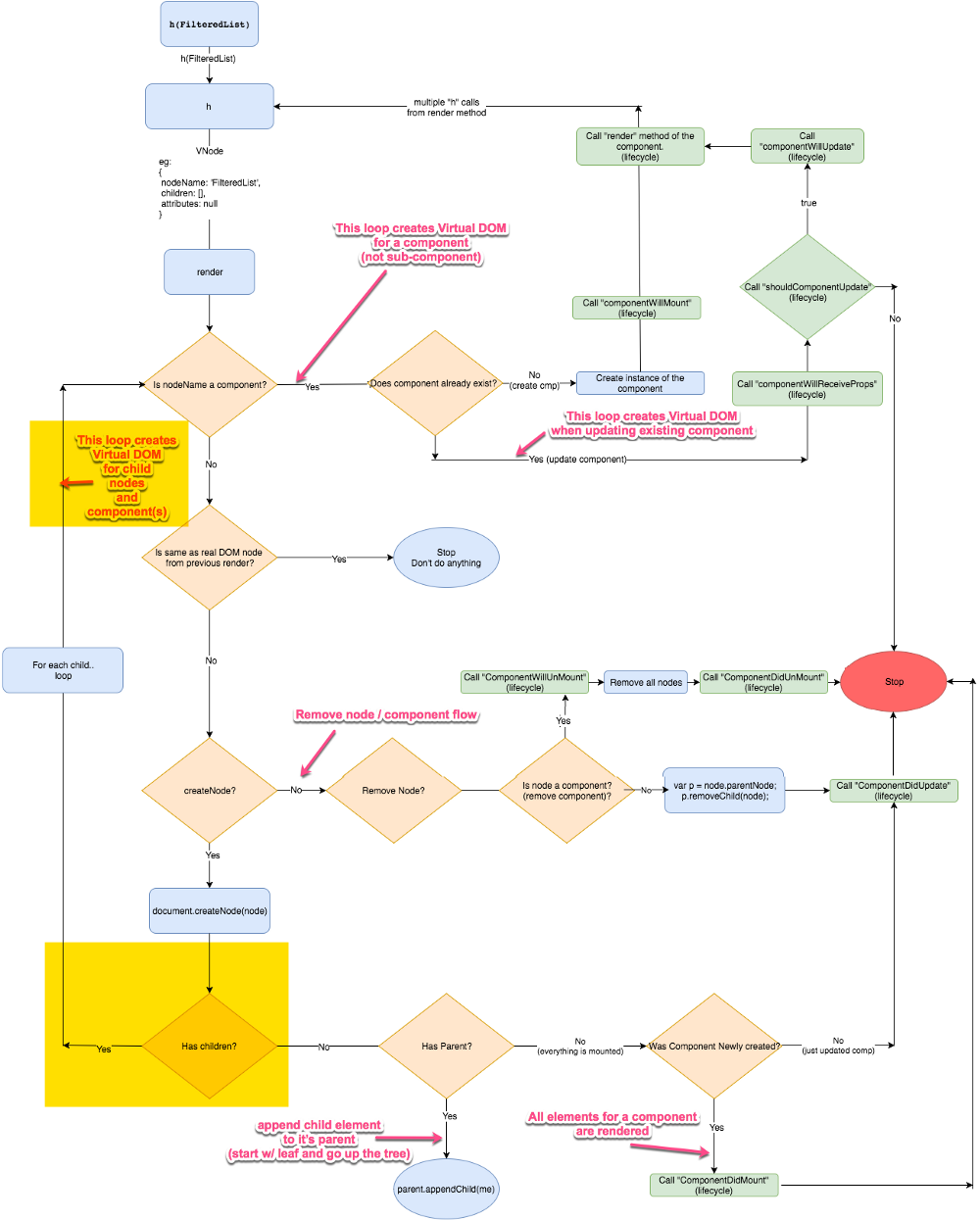
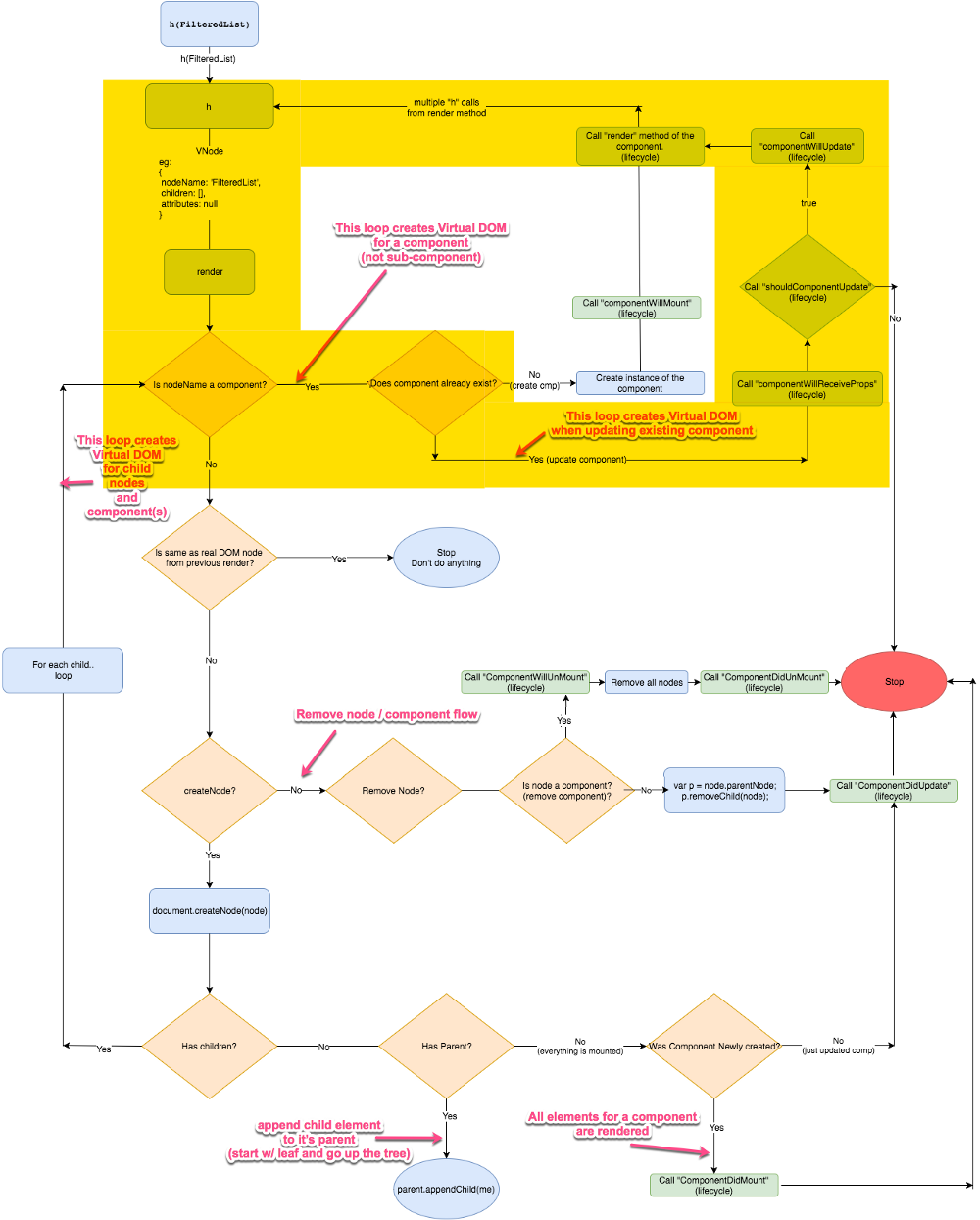
Preact 的虚拟 DOM 算法流程图
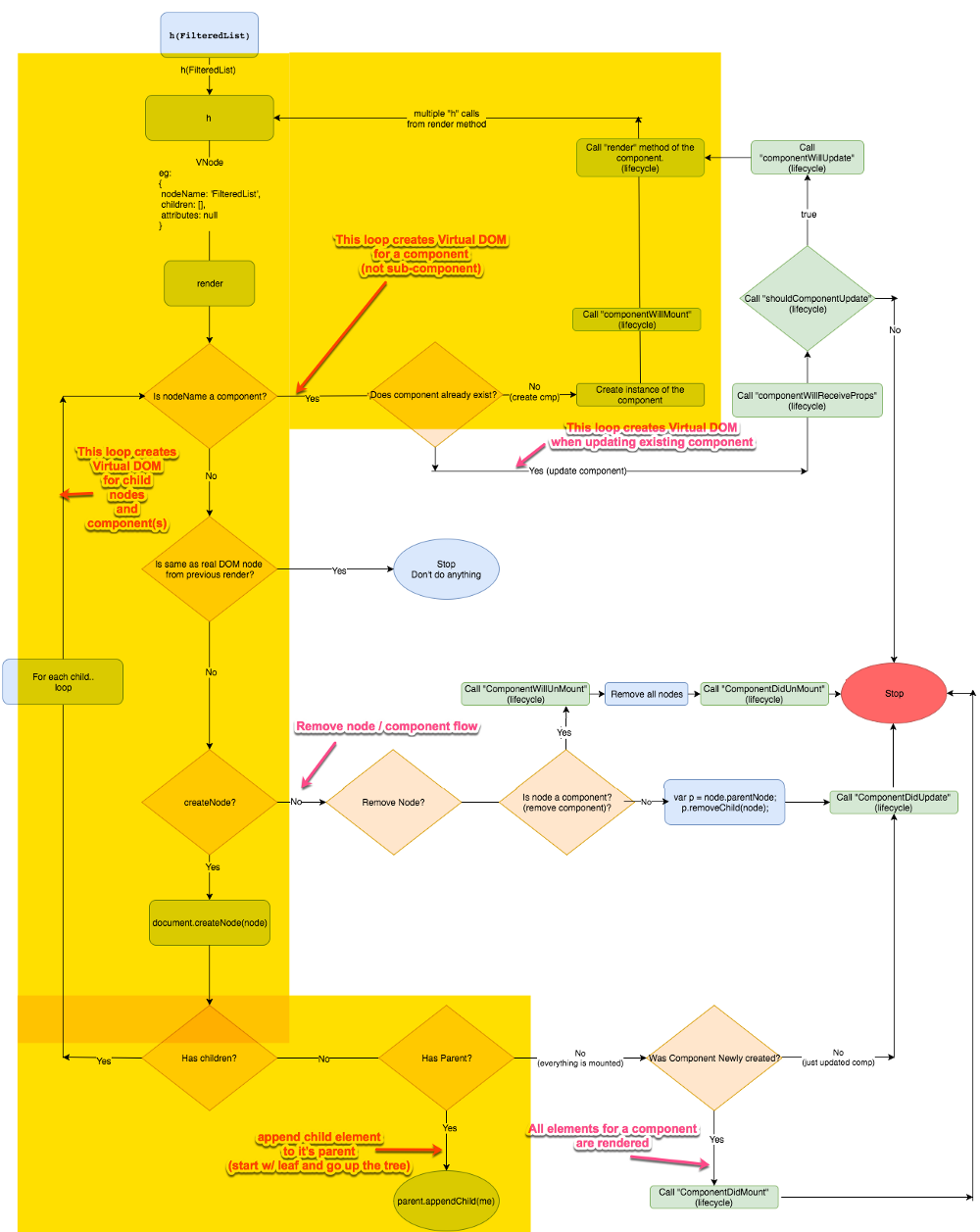
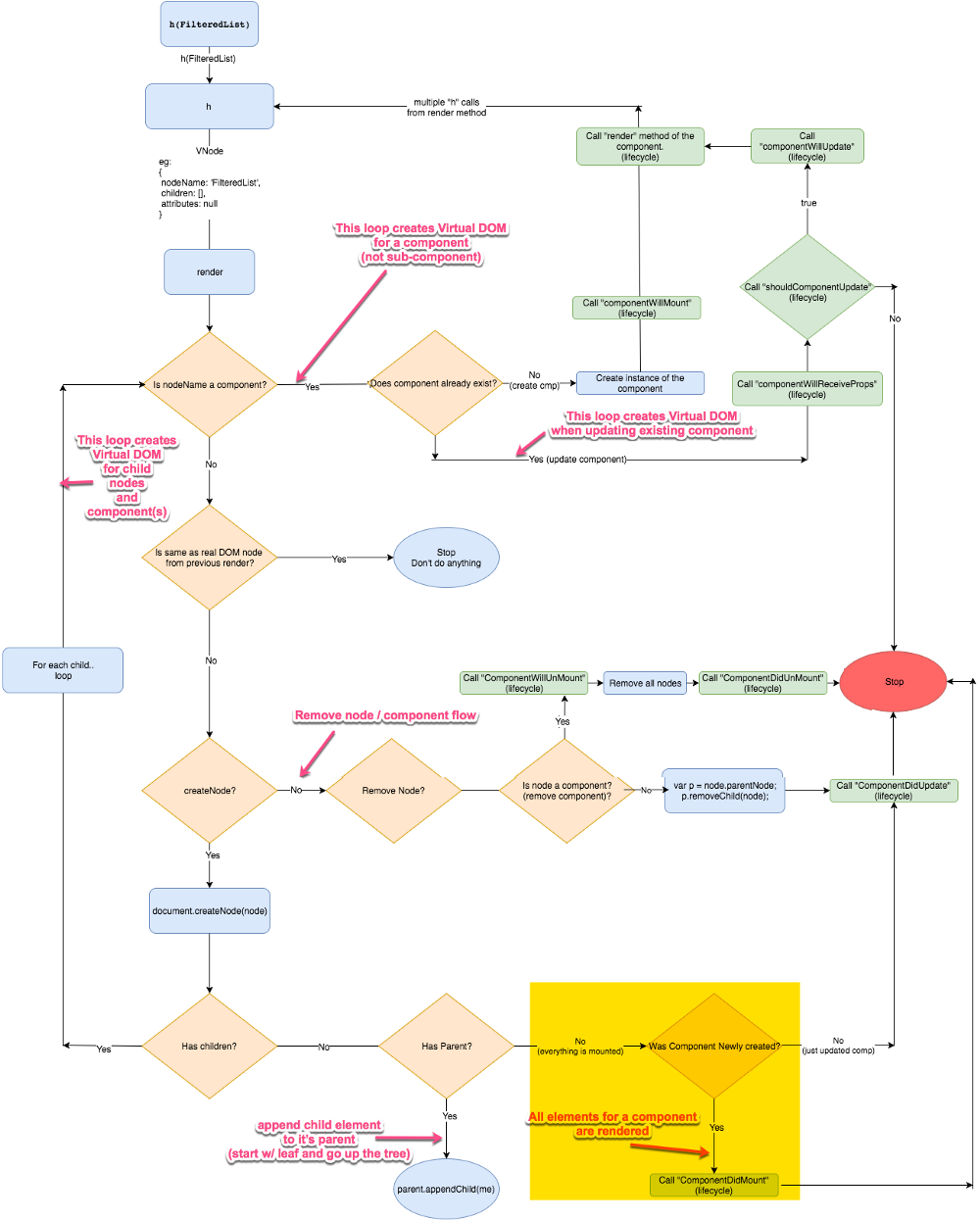
下面的流程图中展示了 Preact 是如何创建、更新、删除组件以及其子组件的。同时它也展示了诸如 componentWillMount 等生命周期事件是何时被调用的。
**注:**这个图看上去很复杂,不要担心,我们会逐个分章节一步一步地详细介绍。
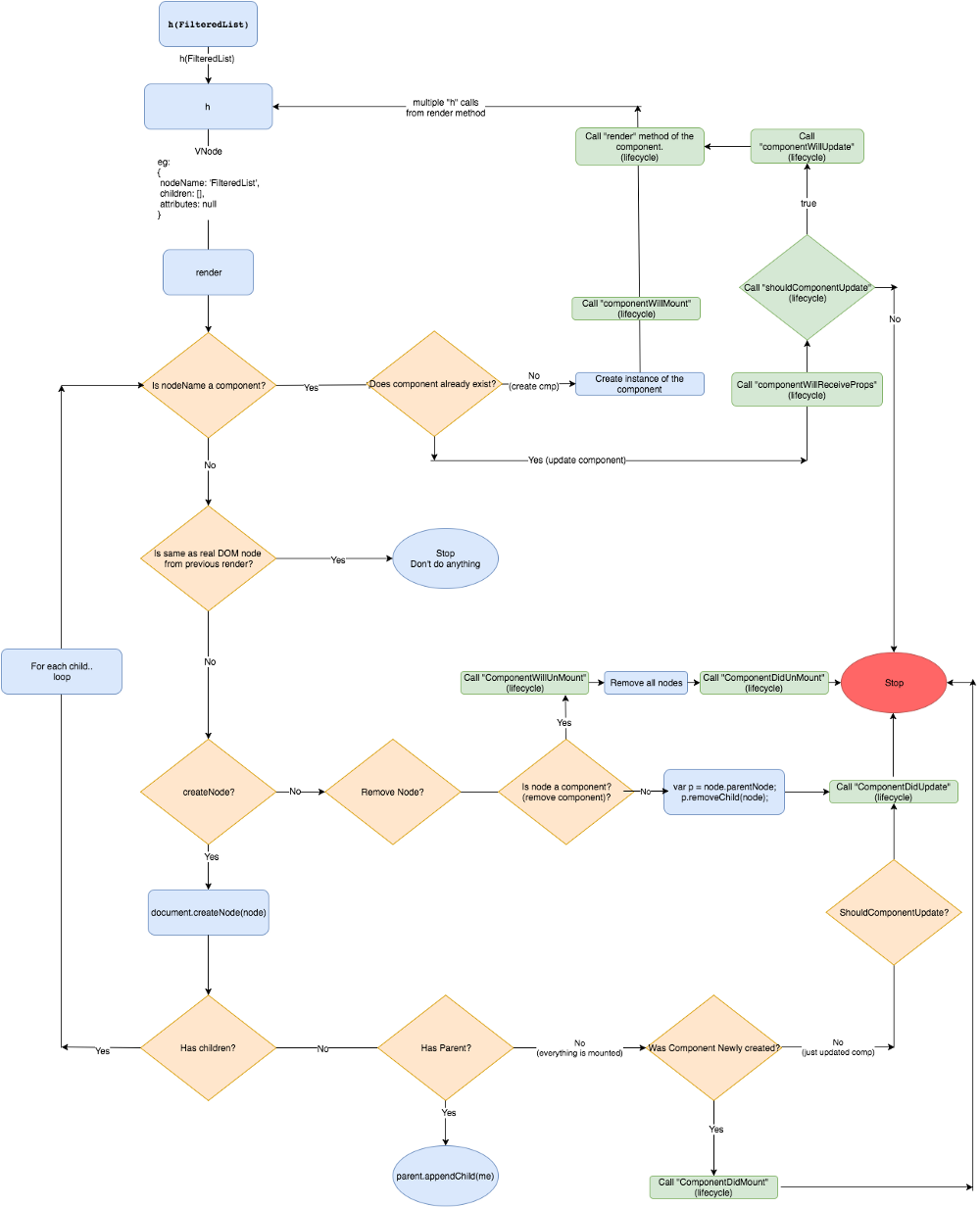
是的,很难一次全部读懂它。所以让我们把它分解成多个章节,一步一步来介绍。
**注:**当我们讨论生命周期中的某部分时,我会在图中用黄色高亮区域把它们标注出来。
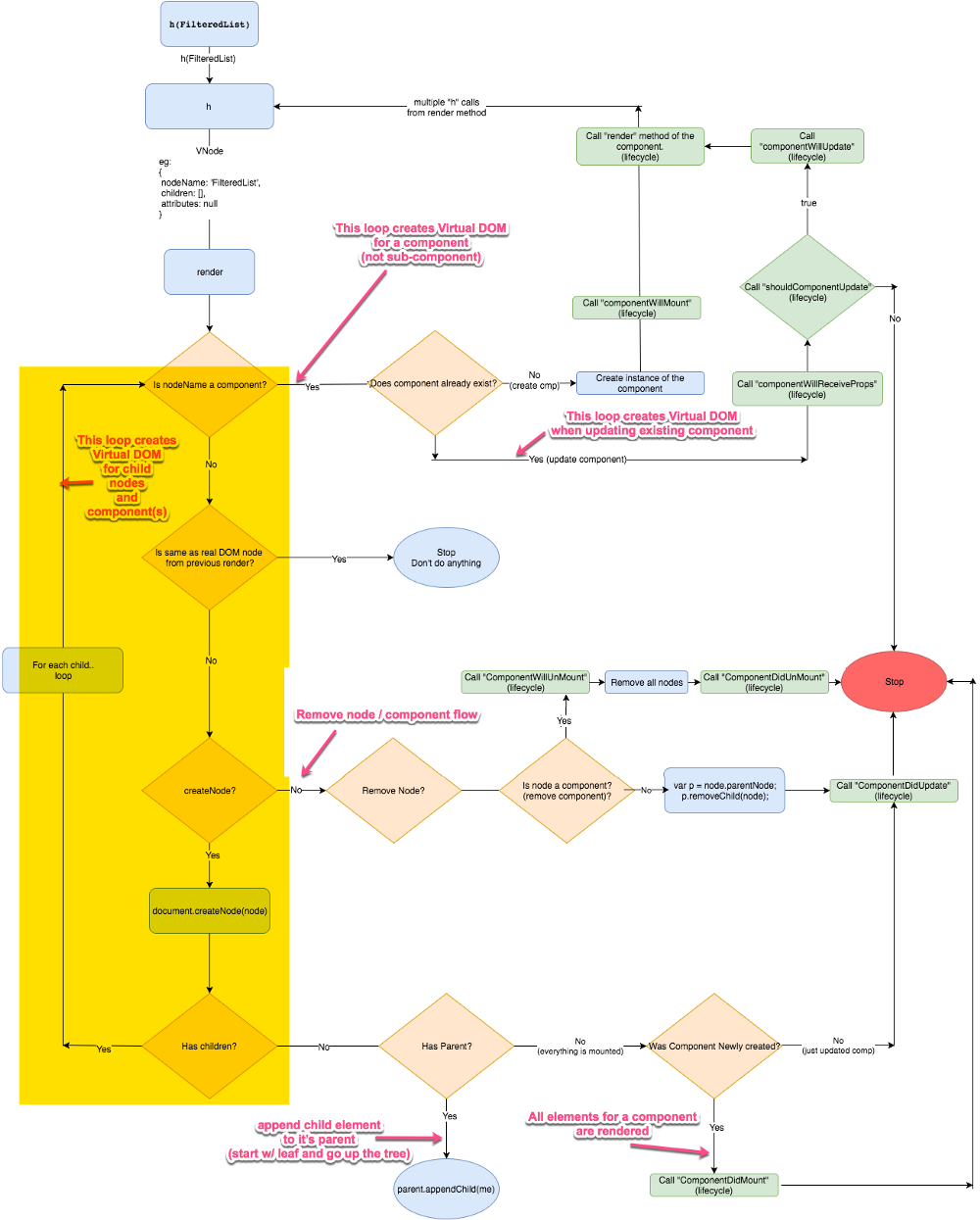
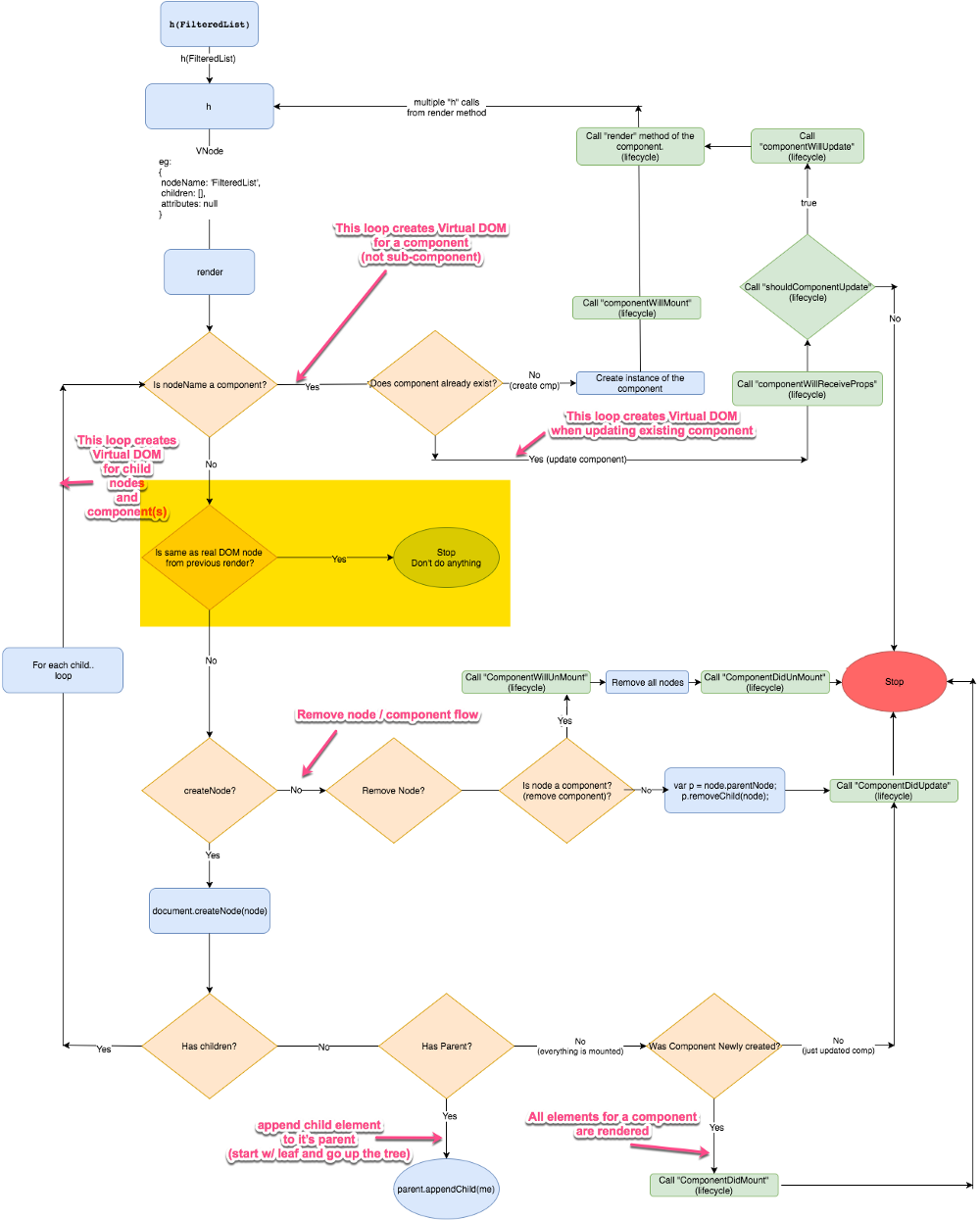
场景1:应用程序的创建
1.为给定的组件创建 VNode (Virtual DOM)
图中的高亮区域展示了创建组件 VNode(Vitual DOM) 树的循环。注意这里没有创建子组件的 VNode,那是另外一个循环。
黄色高亮的部分展示了 VNode 的创建过程
下面这张图展示了我们的应用首次加载时发生了什么。框架完成时得到了 FilteredList 组件的一个带有子结点和属性的 VNode。
**注:**在这个过程中,
componentWillMount和render这两个生命周期方法被调用了(注意上图中的绿色框体)。
绝大部分的生命周期事件,诸如:componentWillMount,render 都可以在这里找到。
2.如果不是组件,那么创建一个真实 DOM
在这一步中,我们会为父结点(div)创建真实的 DOM 元素,并且遍历处理子结点(input 和 List)。
高亮的部分展现了为子组件创建真实 DOM 的处理过程
如下图所示,现在我们就得到了 div:
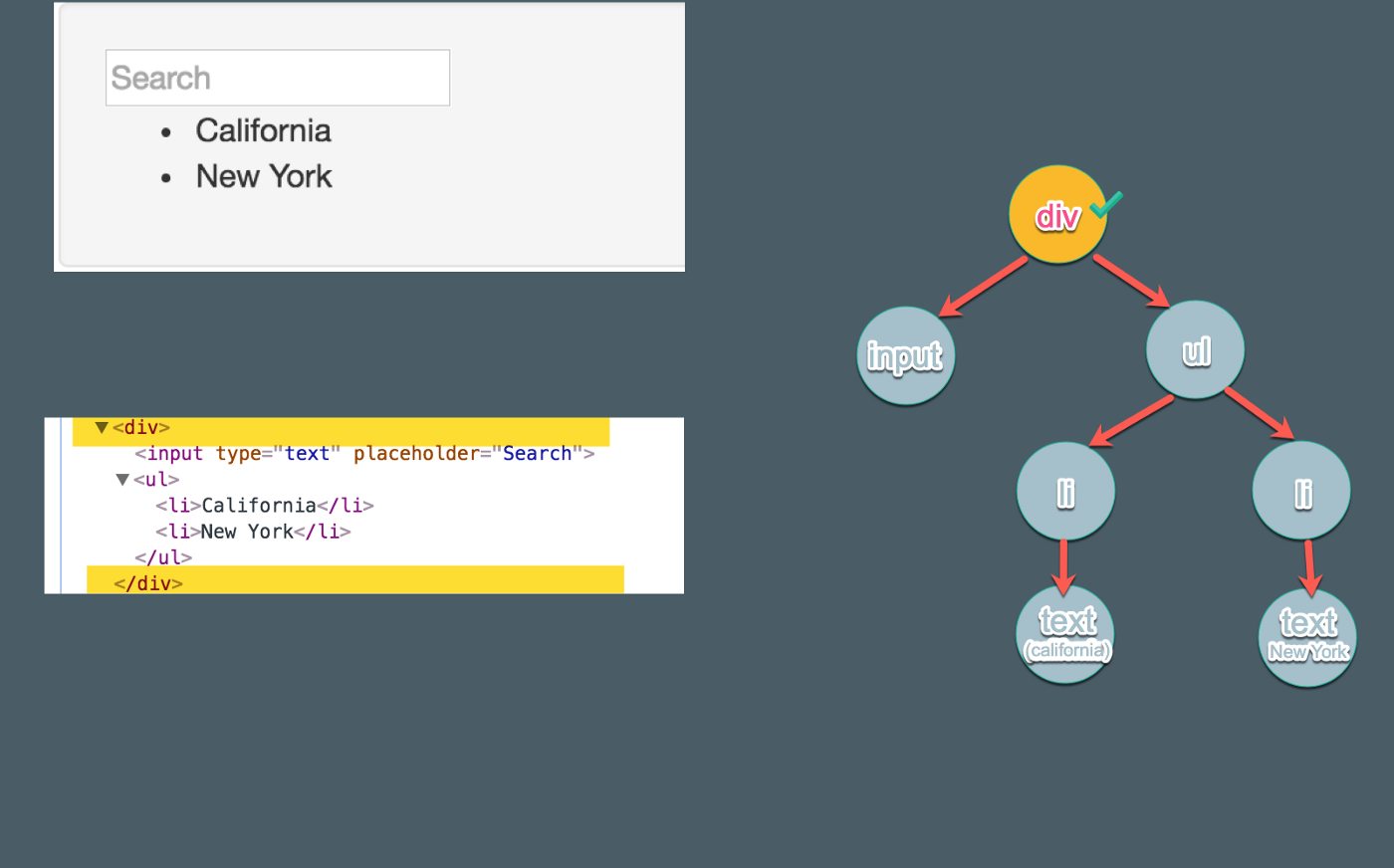
相关代码document.createElement可以在这里查阅。
3.重复子结点
现在,这个循环是对每个子结点重复以上动作。在我们的应用中,我们将会重复 input 和 List。
4.处理子结点并添加将其添加到父结点
在这一步中,我们会处理子结点。由于 input 拥有父结点 div,我们就把 input 作为子结点添加到 div 中。接着 input 的处理流程结束,继续处理 List( div的第二个子结点)。
此时,我们的应用是这样的:
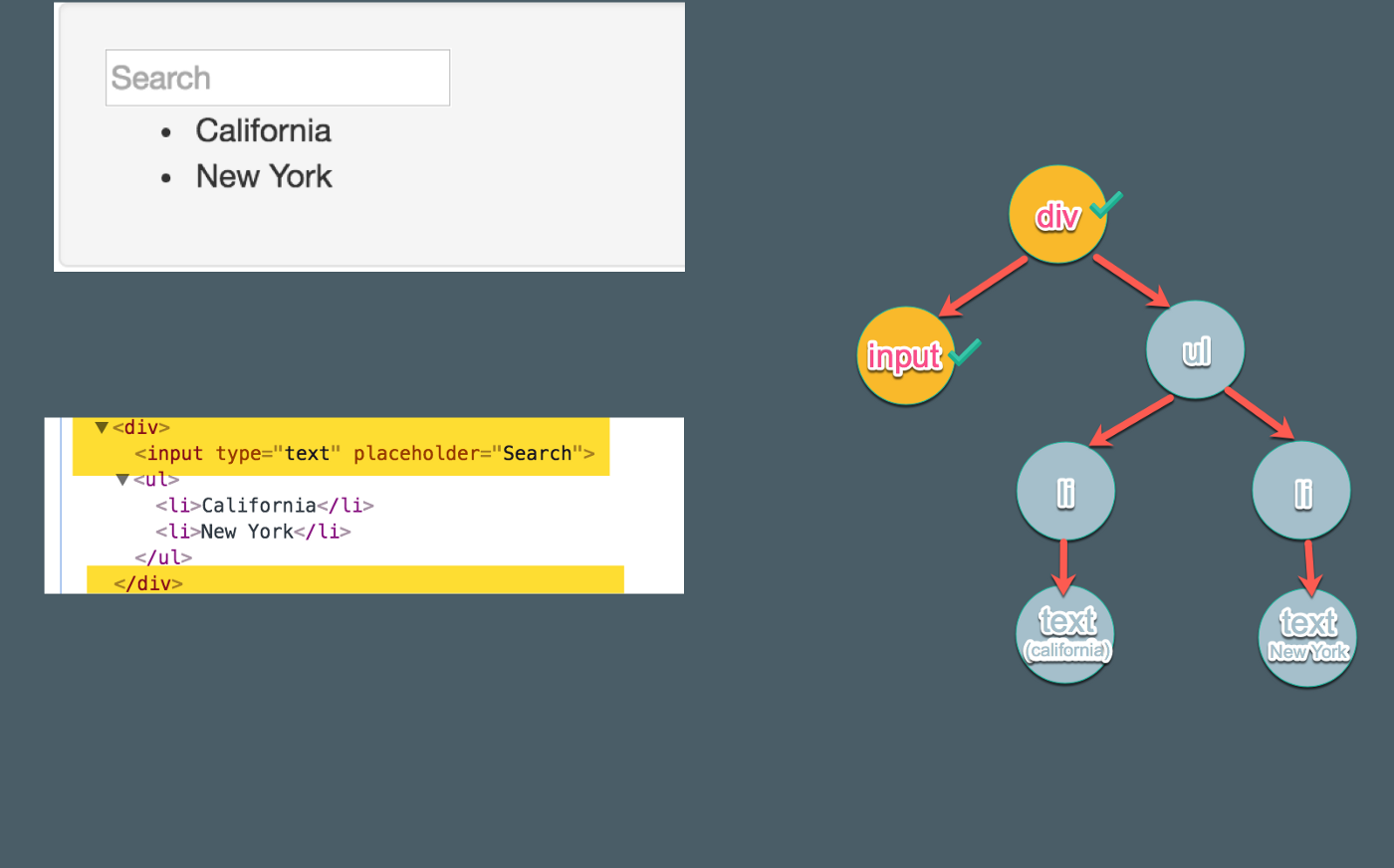
**注意:**在创建 input 之后,由于它没有任何子结点,因此对它的处理结束。但这里并不是立即继续循环并创建 List。而是先将 input 添加到父结点 div,而后再返回处理 List。相关代码appendChild。
5.处理子组件
控制流程返回到步骤一,对 List 组件开始新的一轮处理。由于 List 是一个组件,所以它也会调用 List 的 render 方法来获取到新的 VNode,如下所示:
当处理 List 组件的循环完成时,我们可以得到 List 的 VNode,如下所示:
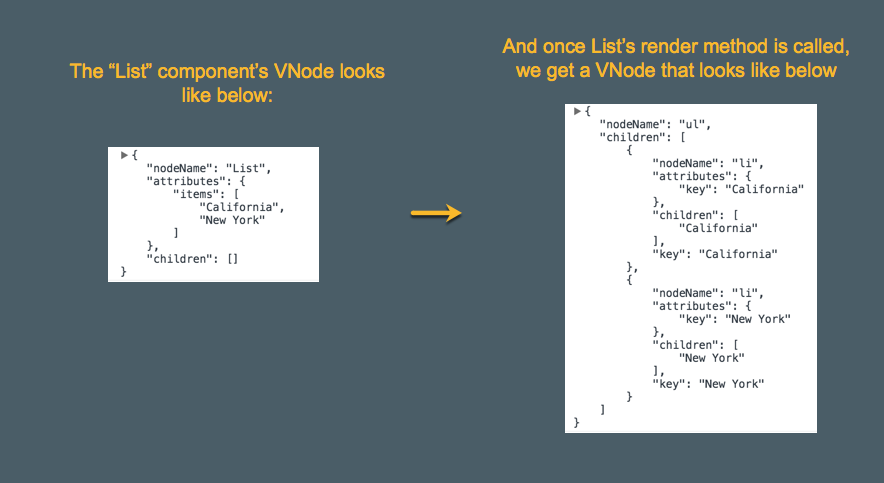
相关代码:buildComponentFormVNode。
6.对所有子结点重复步骤 1到4
现在再次对所有的子结点重复以上处理。一旦到达叶子结点时,就把它添加到父元素上并重复整个过程。
一直重复此流程,直到所有结点都被创建并添加到 DOM 树
下边个张图展示了每个子结点是如何被添加的(提示:深度优先)
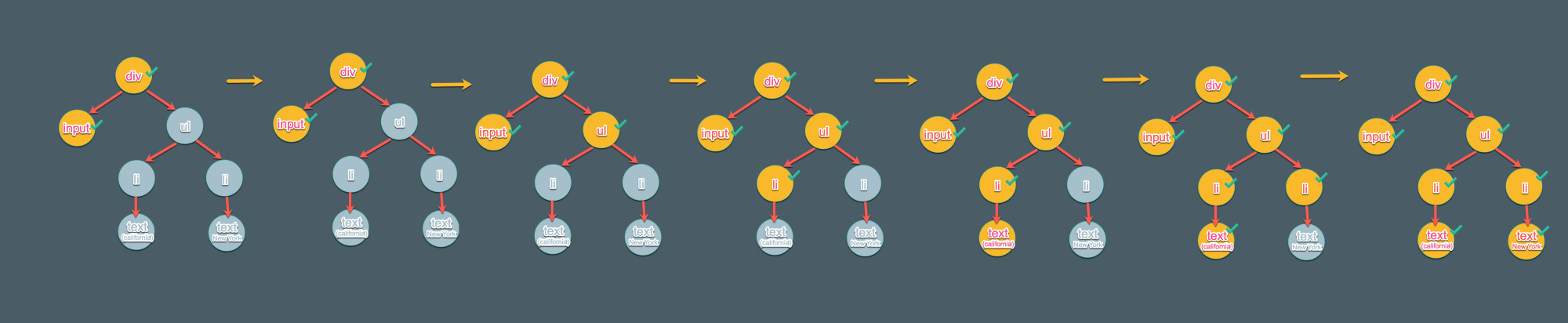
7.结束
此时,我们就完成了整个的处理过程。这里只需要地调用所有组件的 componentDidMount 方法(自子组件开始,至父组件结束),然后停止。
**重要提示:**一旦所有的工作都完成时,我们会将真实 DOM 对象的引用添加到每个相应的组件实例上。这些引用将会帮助完成后续的操作(创建、更新、删除),对比并避免重复创建相同的 DOM 结点。
删除叶子结点
假设我们在 input 中输入 cal 然后回车。这将移除第二个列表结点,另一个叶子结点(New York)则到被保留下来。

好,接下来让我们看一下这一场景的处理流程。
1.以之前一样,创建 VNode
在初始渲染之后的每个变化都称为一个 更新(update) 。对于 更新 周期中的创建 VNode 工作,与前边讲到 创建 周期中的非常类似,就是再来一次创建 VNode。
既然是更新(不是创建)一个组件,那么每个组件以及子组件的 componentWillReceiveProps,shouldComponentUpdate 和 componentWillUpdate 事件将会被触发。
额外的,更新周期,不会再次创建 DOM 元素,因为它们已经存在了。
译者注:如果 DOM 元素可复用就不会再次创建。不可复用的情况主要是指标签名发生变化。这种情况下,我们仍然会创建新的 DOM 元素,并且会把旧有的 DOM 回收掉。例如从
div变为section,那么就会创建一个新的section元素,替换原有div,而div会被回收;
相关代码removeNode和insertBefore。
2.使用真实 DOM 结点引用 & 避免重复创建结点
之前有提到过,在初始化过程中完成创建之后,每个组件都会有一个指向到对应的真实的 DOM 树结点的引用。下边的图片展示了我们演示 app 当前状态的引用关系。
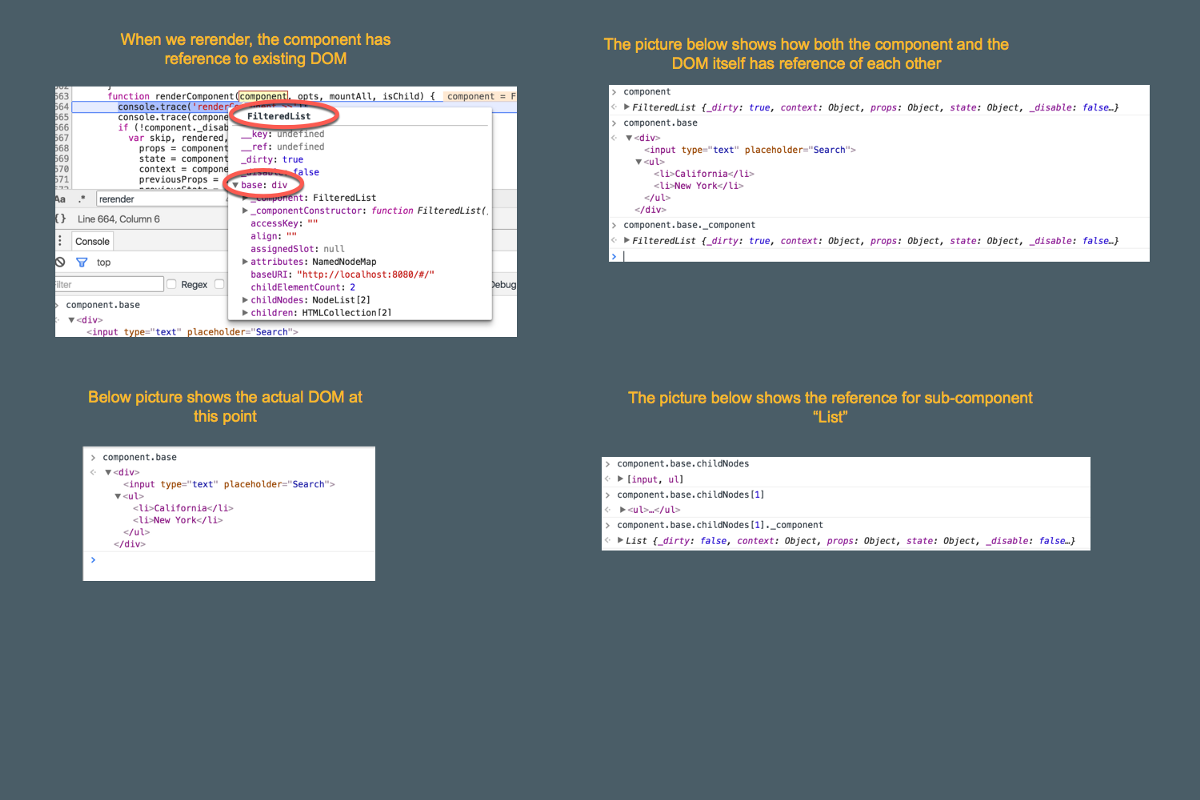
每当我们创建一个新 VNode 时,它的每个属性都会与对应结点的真实 DOM 属性做对比。如果真实 DOM 所有属性都与新的 VNode 一致,那么就会继续处理下一个结点。
译者注:
实际上,这里的逻辑并不是简单地把
VNode与DOM的attributes作对比。在 preact 中,每个 DOM 都有一个
Symbol(__preactattr__)的属性,这里称之为属性缓存。这个属性的值就是我们的VNode的所有属性(不包含children)。我们是用这个属性缓存与 VNode 作对比的。具体的
diff过程大概是这样的:首先,我们会先在 DOM 上找
Symbol(__preactattr__)的属性;如果这个属性不存在,那么我们会遍历 DOM 上所有的attributes来生成它。接着,我们一一对比 VNode 和 属性缓存 的所有属性。如果两者完全一致,那么我们不会对 DOM 做任何更新操作;如果 VNode 与这个属性存在差异,我们则会更新 DOM 属性,并同时更新属性缓存。注意,这里 VNode 的属性对比完成时,也同时完成了对 DOM 的更新。
相关代码:
3.移除多余的 DOM 结点
下边这张图展示了真实 DOM 与 VNode 之间的差异:

由于真实 DOM 比 VNode 多了一个 New York 结点,在下边的图中高亮的部分中我们会把它移除掉。同时,在所有过程完成之后,还会触发生命周期中的 componentWillUnmount 事件。
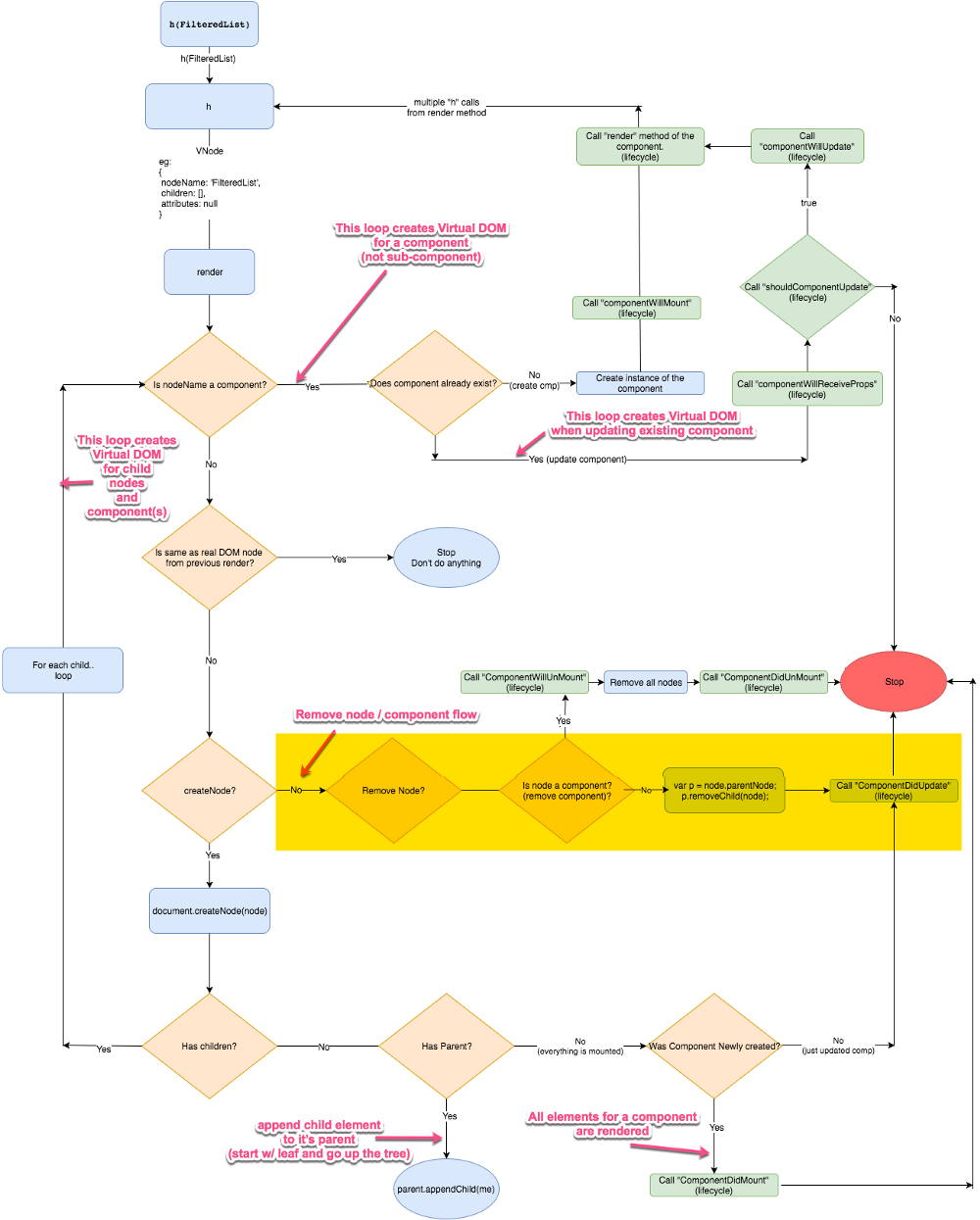
相关代码unmountComponent
移除整个组件
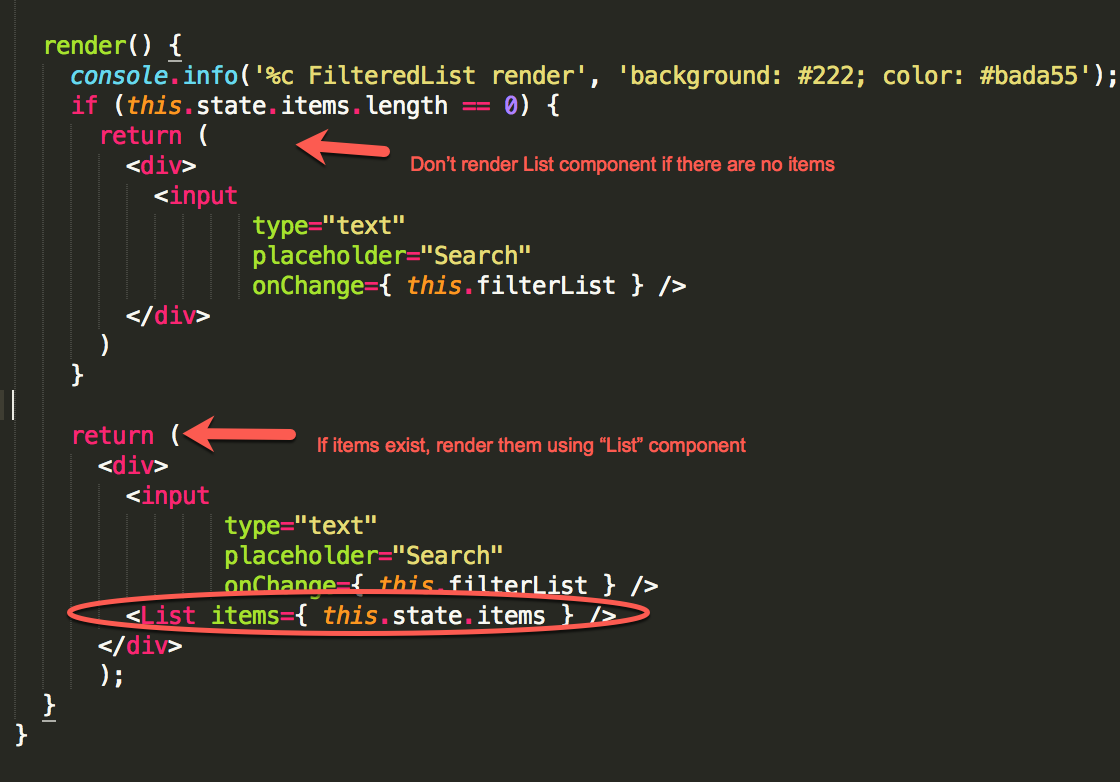
假设我们在筛选框中输入 blabla。那么 “California” 或者 “New York” 都匹配不上,所以我们根本不会去渲染子组件 List。这意味着,我们需要卸载整个组件。
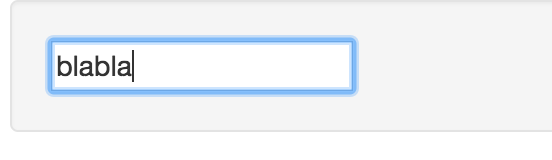
如果没有结果,那么列表组件会被移除
移除一个组件与移除一个结点类似。当我们移除一个有组件引用的 DOM 结点时,会触发组件的生命周期处理函数 componentWillUnmount,接着递归地删除所有的子孙 DOM 结点。所有的元素都被删除时,会触发引用组件的生命周期处理函数 componentDidUnmount。
下面这张图片展示了 DOM 结点与组件实例之间的引用关系:
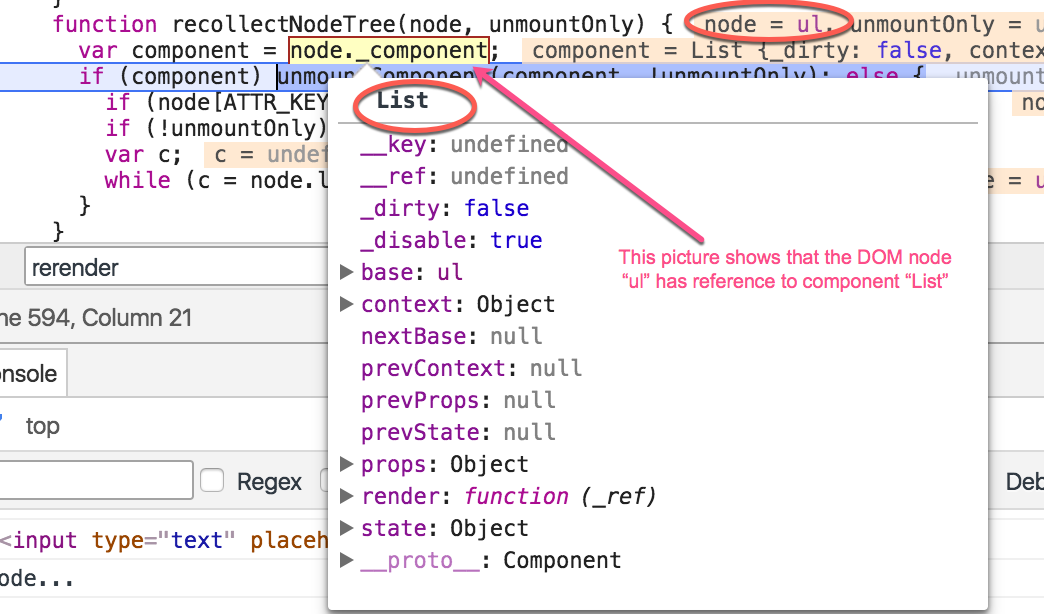
下面的流程图中高亮的部分展示了移除/卸载组件的处理过程:

移除并卸载组件。相关代码unmountComponent
子结点 diff 算法
**译者注:**对于子结点的
diff计算是 Virtual DOM 算法中至关重要的一个环节。但原文没有涉及到其中的细节,因此译者补充这一小节。
在处理完 VNode 的自身属性后,会对子结点进行 diff 计算;为了提高这个计算的性能,我们在框架中强制要求每个子 VNode 都必须有一个属性 key,字符串类型,并且每个 key 互不相同。我们需要使用 key 来构建索引,加速子 VNode 的匹配过程。
子结点 diff 的过程大概是这样的:
首先,先将当前子 VNode 按属性 key 为键、VNode 为值,构建成一个 Map;这里就是为什么 key 一定要互不相同的原因。如果 key 有冲突,那么这个 Map 就无法构建了。
遍历所有新的子 VNode;使用新子 VNode 的 key,找到在 Map 中的当前子 VNode;
将两者做 diff;实际上是递归整个 diff 算法。没找到对应 VNode 就是新增结点,找到了就是更新结点。将此 VNode 的 key 从 Map 中移除;
最后,把 Map 中剩余的 VNode 全部卸载。相关代码 innerDiffNode
总结
我希望这篇文章可以充分地让大家了解 Virtual DOM 是如何工作的,至少是 preact。请注意我只提到了主要的一些场景,并没有涉及到代码中某些的优化处理。同时,如果你发现了任何问题,请告诉我。我非常乐意更正!5 Sneakers to Celebrate Cinco de Mayo