结合智能选择器的语义化的CSS
本文由白牙根据Heydon Pickering的《Semantic CSS With Intelligent Selectors》所译,整个译文带有我们自己的理解与思想,如果译得不好或不对之处还请同行朋友指点。如需转载此译文,需注明英文出处:http://coding.smashingmagazine.com/2013/08/20/semantic-css-with-intelligent-selectors/,以及作者相关信息
——作者:Heydon Pickering
——译者:白牙
“结构永远服从于功能,这是不变的法则”,建筑工程师“摩天大楼之父”Louis Sullivan如是说。因为工程师不希望让无辜的人们被碾压在巨大的建筑物下,这种大拇指式的规则是相当有用的。在设计中你应该总是以功能为重,然后让结构在结果中呈现。如果你以结构为重,虽然这能够建造出一栋漂亮的摩天大楼,但代价是埋下了许多相当危险的种子。
这些都是关于建筑师的,那么对前端架构师或者“非真正的架构师”来说呢?我们需要遵守这个法则还是忽略它?
随着面向对象的CSS(OOCSS)的出现,越来越多人趋向于“把呈现的语义从文档语义中脱离出来”。借助于类(classes)的非特指含义,我们能够以分离的方式来管理一个文档和一个文档的外貌。

在这篇文章当中,我们会探索多种为Web文档添加样式的方法,他们能把文档语义与视觉设计相结合在一起。通过“聪明的”选择器的使用,我们通过这种方法给你讲解怎样去查询语义化的HTML文档现有的功能特性,以此作为对那些格式良好的标记的一个奖励。如果你的代码是正确的,你一定会得到你所期望设计出来的东西。
我想,如果你和我一样同时在开发几个不同的项目,我希望通过这些方法会简化你的工作流程和并能更轻松地穿梭在这些项目当中。另外,在最后的部分我们会讲解一个更被动的方法:我们会制作一个包含属性选择器的CSS书签来测试那些写得很糟糕的HTML文档并使用伪元素来反馈错误。
聪明的选择器
样式表的发明使我们能够将那些美化HTML文档的代码从HTML文档中分离出来。但它对于我们书写标准的HTML文档方面所带来的帮助并不像遥控器那样为电视机带来了更高质量的电视节目。它只不过把工作变得更加简单。因为我们能够使用一个选择器来为多个元素添加样式。(例如 p 可作用于所有的段落元素),页面的一致性和可维护性也不像以前那样那么令人畏惧。
p 选择器最简单的形式就是智能选择器的一个代表。因为 p 选择器在语义分类方面具有先天的基础。不用开发者多做额外的事情它已经知道怎样确认一个段落以及何时为他们添加样式,非常简单而有效,特别是你想为所见即所得编辑器产生的所有的段落元素添加样式的时候。
但如果说它是智能的选择器,那非智能的选择器又是哪些呢?所有需要开发者介入并更改文档从而引起样式上的变化的选择器都被称之为非智能的选择器。class 便是一个经典的非智能选择器因为它不是作为语义约定的一部分出现的。你可以灵活地命名和组织类,但需要一定的思考;除非你在文档上应用它们,否则它们不会自动地执行任何事情。
使用非智能选择器是很消耗开发时间的,因为我们需要手动地为每一个选择器添加对应的不同的样式并把类名复制到每一个需要应用此类的元素。如果我们没有 p 标签,我们不得不使用非智能选择器来管理段落,例如在每一个段落元素中使用一个 .paragraph类来指明。这样做的其中一个缺点是这些样式表不是可移植的,因为你不能再没有为HTML文档的标签指定相应的类名的情况下而应用这些样式到所需要的元素当中。
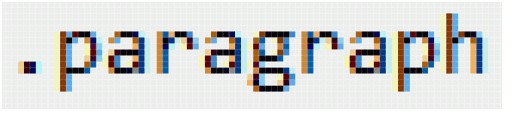
非智能选择器有时候还是有必要的,并且我们很少人会完全依赖智能选择器。然而,一些非智能选择器可能会因为在文档的结构和表现之间搭配不当而变成“愚蠢的”选择器。我将会谈论.button这个使用频率极高的“愚蠢”的选择器。
不同组合的好处
智能选择器并不限制于HTML规范中所提供给我们的基础元素。想要构建复杂的智能选择器,你可以遵从上下文和功能属性的组合来区分基础元素。一些元素,例如<a>,提供了大量的功能差异给开发者考虑和利用。其他的元素,例如<p>元素,任何情景中在明确的功能上没什么差异,但也会根据上下文来承担轻微不同的角色。
header p {
/* styles for prologic paragraphs */
}
footer p {
/* styles for epilogic paragraphs */
}
像这样的简单后代选择器是非常有用的,因为它们让我们能够从视觉上看出一个元素的不同类型而无需从物理上更改底层的文档。这是整个样式表发明的原因:既促进物理上的分离而又无需破坏那些存在于文档和设计之间的概念上的相互关系。
不可避免的,一些OOCSS的粉丝们对这样的后代选择器是有点不太认同的,它们更喜欢像下面这个例子那样来做标记,这是从BEM的“定义”文档中找到的。
<ul class="menu"> <li class="menu__item">…</li> <li class="menu__item">…</li> </ul>
我不会再对后代选择器作进一步的讨论,因为我确定你每天都在使用它们,除非你偏好于上面这种过量的概述。换言之,我们接下来会集中于属性选择器和属性中描述的功能所带来的差异。
超链接属性
即使是那些CSS和HTML之间的概念分离的拥护者也乐于承认一些属性——除了类和自定义数据属性以外的大多数的属性,实际上和文档的内部工作的有重要关系的。没有href属性你的超链接不会链接到任何东西。没有type属性,浏览器无法知道渲染哪一个类型的input元素。没有title属性,你的abbr元素则可能代表任何东西。
像这样的属性有助于改善文档细节的语义化,否则你需要去确认主题元素是否正确被渲染以及运作。如果它们不存在,那么它们应该被创造,如果它们已经存在了,那为什么不适用它们呢?你不能够只写CSS而不写HTML吧。
REL属性
rel属性是链接关系的一个标准属性,是一个描述链接的具体的用途的一个方法。并不是所有的链接的功能都是相同的。得益于众多的WordPress的使用者,rel="prev"和rel="next"成为两个最广泛采用的值,并有助于描述分页博客内容的每个单独页面之间的关系。从语义上来说,一个拥有rel属性的a标签仍然是一个a标签,但我们已经能更加具体地表现它了。这和类不相同,这种具体是从语义上间接表现的。
rel属性应该只被用在合适的地方,因为它们是被HTML的功能规范所维护的,并能因此被不同的用户代理采用从而提高用户体验和搜索引擎的精确度。那么,你曾像下面这样为链接添加过样式吗?使用简单的属性选择器,如:
[rel="prev"] {
/* styling for "previous links" */
}
[rel="next"] {
/* styling for "next" links */
}
属性选择器被所有的浏览器所支持除了最古老和落后的浏览器(IE6),因此只要这个属性存在于标签中的时候没有任何理由不去使用它们。在它的优先级方面,它和类具有相同的权重值。然而,我记得它被建议,我们应该将文档和表现语义分离。我不想浪费这个rel属性,所以我最好元素设置一个毫无意义的属性并通过它来进行样式的添加。
<a href="/previous-article-snippet/" rel="prev" class="prev">previous page</a>
此处首先要注意的第一件事情是,上面元素中唯一没有对文档的语义有帮助的是类这个属性。换句话说,类在上面的文档中式唯一的没有起到什么功能上的作用的东西。在实际中,这意味着类是唯一的打破了分离定律的并被解释为:它实际存在于文档中却又没对文档的结构有任何帮助。
好了,说了这么多抽象的概念,但它的可维护性方面如何?大家都接受使用class作为样式钩子,让我们看看当通过编辑或重构时移除了一些属性的时候会发生什么事情。假设我们使用了伪元素来为[rel="prev"]链接的文字前面添加一个左指箭头:
.prev:before {
content: '\2190'; /* encoding for a left-pointing arrow ("←") */
}

移除类的同时也会同时移除了伪元素,反过来说这个举动会将箭头所移除。但没有了这个箭头,将没有其他的东西能告诉我们链接现存的prev关系。出于同样的原因,移除rel属性也会导致箭头的不完整:因为虽然class会继续让这个箭头得以显示,却总是使文档的状态关系丢失。只有直接的通过语义的属性来给出样式并应用,你才能让你的代码和你自己保持真实。只要是文档中存在的真实的功能,你就要让它被看见。
属性字串
我可以想象你正在想什么:“这很有趣,但在超链接中有多少个这样的语义样式钩子?我还是会不得不依赖类来应用样式。”那么请你看看下面不同的链接功能的不完全的列表吧,所有都是以a元素为基础的:
- links to external resources,
- links to secure pages,
- links to author pages,
- links to help pages,
- links to previous pages (see example above),
- links to next pages (see example above again),
- links to PDF resources,
- links to documents,
- links to ZIP folders,
- links to executables,
- links to internal page fragments,
- links that are really buttons (more on these later),
- links that are really buttons and are toggle-able,
- links that open mail clients,
- links that cue up telephone numbers on smartphones,
- links to the source view of pages,
- links that open new tabs and windows,
- links to JavaScript and JSON files,
- links to RSS feeds and XML files.
这就是链接功能上的差异,所有的类型都可以被用户代理所识别。现在让我们思考一个问题,为了让所有的这些具体链接类型都执行不同的功能,它们必须要有不同的属性。也就是说,为了执行不同的功能,链接的书写形式是需要有所变化的;并且,如果它们书写形式不同,它们就可以通过这个来添加不同的样式。
在准备这篇文章的时候,我对一个构思作了一个检验,命名为Auticons。Auticons是一个图标字体和样式表,用于自动地为链接添加样式。里面的所有选择器都是属性选择器而没有一个类,为格式良好的超链接来调用样式。

在许多的案例中,Auticons 对href值的一个子集进行了查询来确定超链接的功能。通过的它们的属性值的开头或结尾来对相应的元素添加样式,又或者是根据它们属性值是否包含了一个指定的字串来查找对应元素也是可能的。下面是一些常普通的例子。
安全协议 每一个格式良好的URL(例如:绝对地址的URL)会以一个URI scheme 加一个冒号开始。在网络中我们最常见的就是http:,但是mailTo:(用于简单邮件传输协议SMTP)和tel:(用于电话号码)也是很常用的。如果我们可以知道超链接的href的值会如何开始,我们可以利用这个约定来作为样式钩子。在下面的用于安全页面的例子,我们使用^=比较器,意思为“以...开始”。
[href^="https:"] {
/* style properties exclusive to secure pages */
}

在Auticons 中,根据一个特定的用于识别href属性的语义模式,连到安全页面的链接用一把锁来做装饰。这样做的优点是:
- 安全页面的链接 —— 也仅仅是安全页面 —— 能够通过一把挂锁来作使它像是一个安全页面链接。
-
那些不再链接到安全页面的链接会失去
http协议同时用作比喻的挂锁也会消失。 - 新的安全页面的链接也会自动采用这个挂锁来标志这个链接。
当应用于动态内容的时候,这个选择器显得相当地智能。因为安全链接具有它特定的URI scheme,所以属性选择器能够预料到它的调用:一旦编辑器键入一些包含安全链接的内容,链接便会自动应用样式来给予用户一个它是一个安全链接的感觉。因为不需要什么类以及对HTML进行编辑,所以简单的Markdown 中的链接是这样的:
[Link to secure page](https://payment.example.com/)
但要注意的是使用 [href^="https:"]也不是永远正确的,因为也不是所有的 HTTPS 真正安全的。不过,这仅仅是当浏览器本身不太可靠的情况下。专业的浏览器都会在显示 HTTPS 的时候在地址栏渲染一个挂锁。

文件类型
正如我说过的,你也可以通过 href属性以什么结尾来为超链接添加样式。在实践中,这意味着你可以使用CSS来指出链接所指向的文件类型。Auticons 支持.txt, .pdf, .doc, .exe和其他的一些格式,下面是.zip格式的一个例子,使用$=来决定href以什么结尾:
[href$=".zip"]:before,
[href$=".gz"]:before {
content: '\E004'; /* unicode for the zip folder icon */
}
组合
你知道如何在一个元素中添加多个类的方法来建立样式吧?很好,其实你可以用属性选择器来帮你自动完成这些工作。让我们来对比一下:
/* The CSS for the class approach */
.new-window-icon:after {
content: '[new window icon]';
}
.twitter-icon:before {
content: '[twitter icon]';
}
/* The CSS for the attribute selector approach */
[target="_blank"]:after {
content: '[new window icon]';
}
[href*="twitter.com/"]:before {
content: '[twitter icon]';
}
(注意,*=比较器的意思是“内容”,如果href的值包含字串twitter.com/,那么样式便会应该到该元素上)
<!-- The HTML for the class approach --> <a href="http://twitter.com/heydonworks" target="_blank" class="new-window-icon twitter-icon">@heydonworks</a> <!-- The HTML for the attribute selector approach --> <a href="http://twitter.com/heydonworks" target="_blank">@heydonworks</a>

任何负责添加一个到Twitter 页面的超链接的内容编辑器,现在只需要知道两件事:URL和如何在新标签中打开。因为属性选择器能帮助他们找到对应的超链接。
继承
还有一些没有考虑到的地方是:如果有一个不匹配任何属性选择器的链接呢?如果这个超链接是一个普通的旧超链接呢?这个选择器是一个很容易被记住的并且追求性能极致的人会很乐意听到这种话“已经没有别的比它还要更简练了”。
层叠的属性选择器的继承性与和类层叠在一起的时候是一样的。首先,它会对你的a添加样式 —— 假设是一个 text-decoration: underline规则来提高链接的可访问性;然后使用你所提供的属性选择器来为相应的a元素进一步添加层叠的样式。像IE7 这样的浏览器并不完全支持伪元素。但因为继承的关系,链接还是会应用a选择器中的样式。
a {
color: blue;
text-decoration: underline;
}
a[rel="external"]:after {
content: '[icon for external links]';
}
实际的按钮应该是真实的
在下面的部分,我们会详述我们这个CSS书签的结构来讲解代码上的错误。在做这件事前,首先让我们来看看可能会有什么糟糕的选择器潜入我们的工作流程中。
OOCSS的信徒们仍然坚持使用类因为它们是可重用的,就像组件一样。因此,.button比#button更好。不过,我能想到更好的按钮样式的选择器。它的名字也很容易记住。
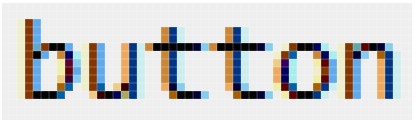
The <buttonelement represents a button. – W3C Wiki
Topcoat是一个OOCSS的基于BEM的UI框架,来自Adobe。Topcoat中的各种各样的按钮样式代码超过了450行,如果把注释块也加进去的话。里面的注释块建议我们用类似这个例子的方式来应用按钮的样式。
<a class="topcoat-button">Button</a>
这个不是一个button。因为,如果它是一个按钮,应该是使用<button>来做标签。实际上,在每一个我们已知的浏览器中,如果使用<button>来表现一个按钮而不添加任何样式,它默认看起来也会像一个按钮。但上面这个例子不是的,因为它用的是<a>标签,本应该是代表一个超链接,实际上,它缺少一个href,这意味着它甚至不算是一个超链接。在技术上,它只是一个占位符,一个没有完成的不完整的超链接。

一只穿着鲨鱼服装的小狗并不是鲨鱼
Topcoat的CSS中的示例仅仅是一个范例,但前提是类定义了元素并且HTML不是欺骗性的(你应该使用button标签而不是a标签来描述按钮)。再多的“有意义的断字”的类名添加也不能弥补你这样丑陋地使用非智能选择器和犯下的代码上的错误。
更新:因为写了这篇文章,Topcoat.io 已经使用<button>标签来取代上面那个例子。这简直太棒了!然而,我对它们使用.is-disabled类来指明这个按钮是禁用的而忽略了disabled属性持保留意见。你可以在评论区看到我和Topcoat 的代表在这方面的讨论。对与促进OOCSS 所带来的WEB标准的灾难,你可以在 semantic-ui.com中自行发现,它们示例中的“标准按钮”居然是一个包含空的<i>标签的<div>标签。
看见是么就是什么
“如果它看起来像只鸭,游泳时也像只鸭,叫声也像只鸭,那么它可能是一只鸭。”
一个装饰得像按钮一样的链接,并且还能触发像点击按钮那样的Javascript 事件,对很多人来说,它是一个按钮。然而,这只意味着它已经通过了前两个阶段的“鸭测试”。为了让所有的用户能够运用归纳推理和辨别按钮,它也必须像这样。因为它仍然是一个链接,尽量避免这种不必要的混淆,因为这种辅助技术的使用者没有追求一个完美语义但这又恰好是我们应当承担的职责。
尽管如此,有些人还是坚持用a作为按钮的标签。超链接是比较容易完全重新地样式化的一个元素。如果选择a标签作为元素,那么只有一个办法让它接近真正的按钮。你猜对了:你必须使用WAI ARIA role 属性值来指明它的含义。可以仅仅通过下列的属性选择器来确认一个超链接因为某些原因看起来像是一个按钮。
[role="button"] {
/* semantic CSS for modified elements that are announced as “button” in assistive technologies */
}
质量保证的属性选择器
“CSS给予了class 属性强大的力量,作者可以基于那些没有任何表现的元素(例如DIV和SPAN)在想象中设计他们的“文档语言”,并通过class 属性来赋予他们样式信息。作者应该避免这种行为即使这种文档语言的结构元素经常得到大家认可和接受它们的意义。” – “选择器,” CSS Level 2, W3C
我们具有a和 button两个元素的原因是为了在语义上划分两种完全不同的功能交互。超链接代表着你将会去到的某个位置的符号,而按钮是作为事件或者动作的触发源。一个是关于位置移动的,另一个则是侧重于转换的。一个是促进脱离的,另一个是促进结合的。
为了确保我们不会做什么愚蠢的事情来让我们的按钮和超链接产生混淆。我们会创建一个使用智能属性选择器的CSS书签并来测试两个元素各自的有效性和质量。
受到Eric Meyer的文章的一点启发以及从DiagnostiCSS 中获取了一些线索,这个样式表会结合属性选择器和:not选择器(或者非伪类) 来在HTML 中把问题高亮出来。与其他的两种实现不同,它会使用伪元素来将错误打印到屏幕上。每一个错误都会采用漫画字体以及粉红色的背景来显示。
通过把功能和表单连接起来,我们可以看到丑陋的HTML 会间接地导致丑陋的 CSS。这是设计师滥用文档带来的后果。尝试一下把revenge.css保存到你的CSS书签中,并单击这个书签以在任何你喜欢的页面触发它。注意:它不会在服务在https协议上的页面中起作用。
Drag to your bookmarks bar.
规则1
如果它是个超链接,那它就应该有
href属性。
a:not([href]):after {
content: 'Do you mean for this to be a link or a button, because it does not link to anything!';
display: block !important;
background: pink !important;
padding: 0.5em !important;
font-family: 'comic sans ms', cursive !important;
color: #000 !important;
font-size: 16px !important;
}
注意:在这个例子中我并不是要测试属性的值,而是测试这个属性是否有被设置,也就是说,[href]匹配的是任何含有href属性的元素。这个测试仅仅适用于超链接。这个测试可以这样来理解,“对于每一个不具有href属性的元素,为其添加一个伪元素并在伪元素中报告错误提示。”
规则2
“如果这个超链接具有
href属性,那这个属性应该具有值。”
a[href=""]:after, a[href$="#"]:after, a[href^="javascript"]:after {
content: 'Do you mean for this link to be a button, because it does not go anywhere!';
/*... ugly styles ...*/
}
注意:如果这个href属性的值为空或者以# 结尾又或者是使用Javascript,那么它应该是被用作了非<button>标签实现的按钮。注意我使用的是“以javascript开始”,这样可以避免其使用的是javascript:void(0)这样的值。但我们也不能指望它总是以这种方式书写。
规则3
“如果它使用了button 类,那它理应是一个按钮,至少在可访问性层上。”
.button:not(button):not([role="button"]):not([type="button"]):not([type="submit"]):not([type="reset"]):after,
.btn:not(button):not([role="button"]):not([type="button"]):not([type="submit"]):not([type="reset"]):after,
a[class*="button"]:not([role="button"]):after {
content: 'If you are going to make it look like a button, make it a button, damn it!';
/*... ugly styles ...*/
}
注意:这个例子中,我们为你展示了,当测试属性值的时候,你可以怎样来使用链式的否定。每一个选择器可以像这样理解:“如果一个元素具有一个类指明它是一个按钮,但它却不是一个按钮元素,并且没有一个正确的role 值来使它在可访问性层为一个按钮,而且它也不是一个按钮类型的input元素,那好吧。。。你在说谎。”我不得不使用[class*="button"]来捕获Topcoat 里面没有使用role来成为实际按钮的超链接中应用的不同的类(多达62种!)。我注意到有一些开发者在按钮的父元素上使用button-container和其他相似的类名,这就是为什么a修饰符被包含在里面的原因。你可以注意到在Twitter Bootstrap 中使用了.btn类,(如果你仔细阅读了它的组件文档)你会知道这无法确定是否使用链接还是按钮来作为按钮。
规则4
如果一个元素具有
role="button",那么即使没有Javascript它也应该能链接到某个地方。
a[role="button"]:not([href*="/"]):not([href*="."]):not([href*="?"]):after {
content: 'Either use a link fallback, or just use a button element.';
/*... ugly styles ...*/
}
注意:我们可以相当地确定不包含/,.(通常存在于文件拓展名的前面)或?(查询字符串的开端)其中之一的href应该是假的。使链接表现地像按钮并且当javascript开启并return: false的时候是很好的。原因是,当javascript关闭时它也能够链接到某个地方。实际上,这仅仅是我能够想出来的不使用<button>的一个合理的理由。
规则5
“你不能够禁用一个超链接。”
a.button[class*="disabled"]:after,
a.btn.disabled:after,
a[class*="button"][class*="disabled"]:after {
content: 'You cannot disable a hyperlink. Use a button element with disabled="disabled".';
/*... ugly styles ...*/
}
注意:甚至连很古老的用户代理也能识别disabled属性,因此我们可以恰当地把使用在一些合适的元素中。上面的例子可以看出,你可以连接属性选择器,就好像你连接多个类一样:在最后的三个选择器,我们声明,“如果一个超链接的类中包含button字串和disabled字串,就会为其打印错误信息。”Twitter Bootstrap 使用第二种形式,.btn.disabled,在它的样式表中,但并不包含a前缀。如果是用在超链接中我们只会认为它是一个错误。
规则6
“在表单中的按钮应该具有明确的类型。”
form button:not([type]):after {
content: 'Is this a submit button, a reset button or what? Use type="submit", type="reset" or type="button"';
}
注意:我们需要确定表单中的按钮是否具有明确的类型,因为一些浏览器会把所有没有明确类型的button元素设置为type="submit"。如果我们表单中的按钮具有其它的母的,我们必须绝对保证该按钮的类型不是submit。
规则7
“无论是按钮还是超链接都应该具有一些内容在里面或者是具有ARIA label。”
a:empty:not([aria-label]):not([aria-labelledby]):after,
button:empty:not([aria-label]):not([aria-labelledby]):after,
button:not([aria-label]):not([aria-labelledby]) img:only-child:not([alt]):after,
a:not([aria-label]):not([aria-labelledby]) img:only-child:not([alt]):after {
content: 'All buttons and links should have text content, an image with alt text or an ARIA label';
/*... ugly styles ...*/
}
注意:按钮和链接并没有什么明确的用途 —— 在文本和图像的形式上 —— 是相当假的。最后的两个选择器是我写过的最复杂的选择器了。对于超链接的版本,这个选择器应该是这样理解的,“如果一个超链接不具有aria-label属性或aria-labelledby属性,并且它只包含一个图片元素作为内容,但这个图片又不具有alt属性,那就会打印相关的错误信息。”另外,注意这个“:empty选择器”。存在争论的是,那些非自动闭合的元素永远不该被置为空。
总结
在上面的例子中我所用来描述的这些选择器和模式并不是想尝试一些不同的而写一些东西。属性选择器也不是什么新鲜事物。IE 6是唯一的不支持它的浏览器。我使用它们的原因是我没有时间和精力在CSS上写了一遍选择器还要在完全地在HTML在写一遍。我在我的页面的头部使用[role="banner"]而不使用.page-header是因为这是我唯一知道的方法 —— 基于能看到预期的视觉效果 —— 并能够把导航标志放在正确的位置。
没有所谓的语义的CSS,只存在语义的HTML 和它的可见形式。在这篇文章中我已经展示了这些东西,通过将web页面的功能和构成直接地结合,你可以建立奖励和惩罚的机制。一方面,你可以设置选择器对那些被正确使用的标签来添加可见的图案;另一方面,你可以找到那些丑陋的错误的方式应用的标签结构并在页面上打印它们的错误。
老实的说,并不是所有的样式钩子都是完全语义的和智能的。类被描述为一些需要应用的元素以及尚未成为标准的属性的填充物。因此你可以发现 .footer变成了 <footer>以及 type="text"(通过javascript来验证url)变为可以直接使用type="url"来验证url 。其他时候,它在做非语义的布局基于网格框架的脚手架时是非常有用的。
然而,当你决定给予CSS自己完全独立的逻辑时,在功能和结构之间一定会产生不必要的争执。在这种情况下,你只有提高自己的警惕才能让它们不会难以理解和失去效果。更糟糕的是,追求写完全语义化的类的时候往往会让你陷入“什么是语义化的类”的没完没了的讨论当中。你会开始用更少的时间来用遥控器操作电视机而变得花费更多时间站在前面,思考如何使用你的遥控器。
生命很短,请珍惜时间。
译者手语:整个翻译依照原文线路进行,并在翻译过程略加了个人对技术的理解。如果翻译有不对之处,还烦请同行朋友指点。谢谢!
白牙
互联网开发者,关注Web应用开发,前端交互设计。个人博客,多多交流,愿与大家共同进步。
如需转载烦请注明出处:
英文原文:http://coding.smashingmagazine.com/2013/08/20/semantic-css-with-intelligent-selectors/
中文译文:https://www.fedev.cn/css/semantic-css-with-intelligent-selectors.html
Nike Air Force 1 '07 LV8 Crocodile Leather Black Dark Grey 718152-018